
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
REVEALED: Open A.I. Staff Warn "The progress made on Project Q* has the potential to endanger humanity" (REUTERS)
- Thread starter null
- Start date
More options
Who Replied?1/1
"I think at the moment, the power of what you can do with large language models and other forms of generative AI is still just enormously underappreciated," Director of the Stanford AI Lab, Professor Chris Manning at #C3Transform 2024.
Watch here: LLMs: Where Did They Come From? Where Are They Going? Will They Become Sentient? | C3 Transform 2024
"I think at the moment, the power of what you can do with large language models and other forms of generative AI is still just enormously underappreciated," Director of the Stanford AI Lab, Professor Chris Manning at #C3Transform 2024.
Watch here: LLMs: Where Did They Come From? Where Are They Going? Will They Become Sentient? | C3 Transform 2024
July 26, 2026 skynet goes active and starts learning at a geometric rate. scared & in panic they tried to pull the plug but it is too late...
Time to stock up on that oozie nein melemeetah

Uchiha God
Veteran
we're finished
1/5
A simple puzzle GPTs will NEVER solve:
As a good programmer, I like isolating issues in the simplest form. So, whenever you find yourself trying to explain why GPTs will never reach AGI - just show them this prompt. It is a braindead question that most children should be able to read, learn and solve in a minute; yet, all existing AIs fail miserably. Try it!
It is also a great proof that GPTs have 0 reasoning capabilities outside of their training set, and that they'll will never develop new science. After all, if the average 15yo destroys you in any given intellectual task, I won't put much faith in you solving cancer.
Before burning 7 trillions to train a GPT, remember: it will still not be able to solve this task. Maybe it is time to look for new algorithms.
2/5
Mandatory clarifications and thoughts:
1. This isn't a tokenizer issue. If you use 1 token per symbol, GPT-4 / Opus / etc. will still fail. Byte-based GPTs fail at this task too. Stop blaming the tokenizer for everything.
2. This tweet is meant to be an answer to the following argument. You: "GPTs can't solve new problems". Them: "The average human can't either!". You: <show this prompt>. In other words, this is a simple "new statement" that an average human can solve easily, but current-gen AIs can't.
3. The reason GPTs will never be able to solve this is that they can't perform sustained logical reasoning. It is that simple. Any "new" problem outside of the training set, that requires even a little logical reasoning, will not be solved by GPTs. That's what this aims to show.
4. A powerful GPT (like GPT-4 or Opus) is basically one that has "evolved a circuit designer within its weights". But the rigidness of attention, as a model of computation, doesn't allow such evolved circuit to be flexible enough. It is kinda like AGI is trying to grow inside it, but can't due to imposed computation and communication constraints. Remember, human brains undergo synaptic plasticity all the time. There exists a more flexible architecture that, trained on much smaller scale, would likely result in AGI; but we don't know it yet.
5. The cold truth nobody tells you is that most of the current AI hype is due to humans being bad at understanding scale. Turns out that, once you memorize the entire internet, you look really smart. Everyone on AI is aware of that, it is just not something they say out loud. Most just ride the waves and enjoy the show.
6. GPTs are still extremely powerful. They solve many real-world problems, they turn 10x devs into 1000x devs, and they're accelerating the pace of human progress in such a way that I believe AGI is on the corner. But it will not be a GPT. Nor anything with gradient descent.
7. I may be completely wrong. I'm just a person on the internet. Who is often completely wrong. Read my take and make your own conclusion. You have a brain too!
Prompt:
3/5
Solved the problem... by modifying it? I didn't ask for code.
Byte-based GPTs can't solve it either, so the tokenizer isn't the issue.
If a mathematician couldn't solve such a simple task on their own, would you bet on them solving Riemann's Hypothesis?
4/5
Step 5 is wrong. Got it right by accident. Make it larger.
5/5
I'm baffled on how people are interpreting the challenge as solving that random 7-token instance, rather than the general problem. I should've written <program_here> instead. It was my fault though, so, I apologize, I guess.
A simple puzzle GPTs will NEVER solve:
As a good programmer, I like isolating issues in the simplest form. So, whenever you find yourself trying to explain why GPTs will never reach AGI - just show them this prompt. It is a braindead question that most children should be able to read, learn and solve in a minute; yet, all existing AIs fail miserably. Try it!
It is also a great proof that GPTs have 0 reasoning capabilities outside of their training set, and that they'll will never develop new science. After all, if the average 15yo destroys you in any given intellectual task, I won't put much faith in you solving cancer.
Before burning 7 trillions to train a GPT, remember: it will still not be able to solve this task. Maybe it is time to look for new algorithms.
2/5
Mandatory clarifications and thoughts:
1. This isn't a tokenizer issue. If you use 1 token per symbol, GPT-4 / Opus / etc. will still fail. Byte-based GPTs fail at this task too. Stop blaming the tokenizer for everything.
2. This tweet is meant to be an answer to the following argument. You: "GPTs can't solve new problems". Them: "The average human can't either!". You: <show this prompt>. In other words, this is a simple "new statement" that an average human can solve easily, but current-gen AIs can't.
3. The reason GPTs will never be able to solve this is that they can't perform sustained logical reasoning. It is that simple. Any "new" problem outside of the training set, that requires even a little logical reasoning, will not be solved by GPTs. That's what this aims to show.
4. A powerful GPT (like GPT-4 or Opus) is basically one that has "evolved a circuit designer within its weights". But the rigidness of attention, as a model of computation, doesn't allow such evolved circuit to be flexible enough. It is kinda like AGI is trying to grow inside it, but can't due to imposed computation and communication constraints. Remember, human brains undergo synaptic plasticity all the time. There exists a more flexible architecture that, trained on much smaller scale, would likely result in AGI; but we don't know it yet.
5. The cold truth nobody tells you is that most of the current AI hype is due to humans being bad at understanding scale. Turns out that, once you memorize the entire internet, you look really smart. Everyone on AI is aware of that, it is just not something they say out loud. Most just ride the waves and enjoy the show.
6. GPTs are still extremely powerful. They solve many real-world problems, they turn 10x devs into 1000x devs, and they're accelerating the pace of human progress in such a way that I believe AGI is on the corner. But it will not be a GPT. Nor anything with gradient descent.
7. I may be completely wrong. I'm just a person on the internet. Who is often completely wrong. Read my take and make your own conclusion. You have a brain too!
Prompt:
3/5
Solved the problem... by modifying it? I didn't ask for code.
Byte-based GPTs can't solve it either, so the tokenizer isn't the issue.
If a mathematician couldn't solve such a simple task on their own, would you bet on them solving Riemann's Hypothesis?
4/5
Step 5 is wrong. Got it right by accident. Make it larger.
5/5
I'm baffled on how people are interpreting the challenge as solving that random 7-token instance, rather than the general problem. I should've written <program_here> instead. It was my fault though, so, I apologize, I guess.


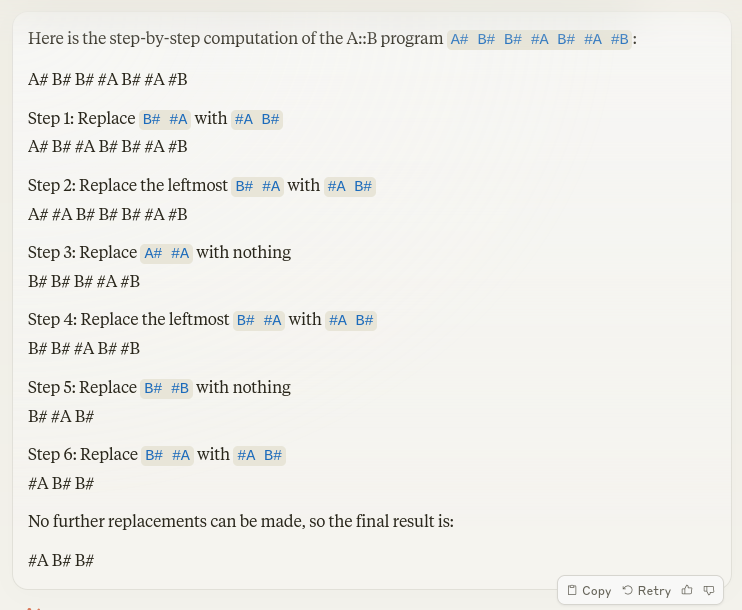
1/7
Solved by getting the LLM to simulate the execution of a program that carefully prints out every state mutation and logic operator
Mapping onto A,B,C,D made it work better due to tokenization (OP said this was fine)
Claude beats GPT for this one
2/7
Was doing this technique way back in 2022
3/7
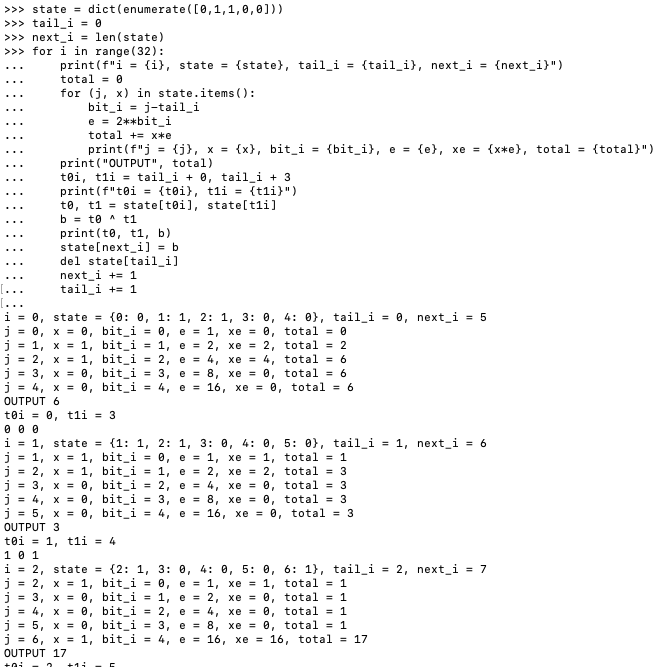
GPT can execute fairly complicated programs as long as you make it print out all state updates. Here is a linear feedback shift register (i.e. pseudorandom number generator). Real Python REPL for reference.
4/7
Another
5/7
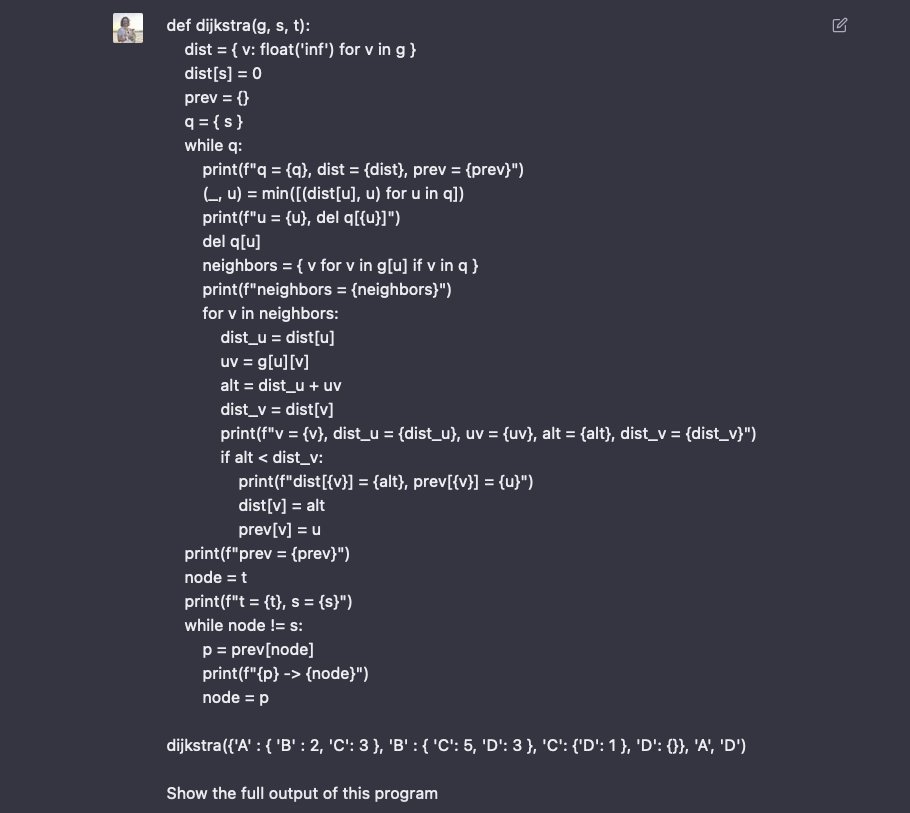
Getting ChatGPT to run Dijkstra's Algorithm with narrated state updates
6/7
h/t
@goodside who I learned a lot of this stuff from way back in the prompting dark ages
7/7
I'll have to try a 10+ token one later — what makes you think this highly programmatic approach would fail, though?
Solved by getting the LLM to simulate the execution of a program that carefully prints out every state mutation and logic operator
Mapping onto A,B,C,D made it work better due to tokenization (OP said this was fine)
Claude beats GPT for this one
2/7
Was doing this technique way back in 2022
3/7
GPT can execute fairly complicated programs as long as you make it print out all state updates. Here is a linear feedback shift register (i.e. pseudorandom number generator). Real Python REPL for reference.
4/7
Another
5/7
Getting ChatGPT to run Dijkstra's Algorithm with narrated state updates
6/7
h/t
@goodside who I learned a lot of this stuff from way back in the prompting dark ages
7/7
I'll have to try a 10+ token one later — what makes you think this highly programmatic approach would fail, though?








1/3
A simple puzzle GPTs will NEVER solve:
As a good programmer, I like isolating issues in the simplest form. So, whenever you find yourself trying to explain why GPTs will never reach AGI - just show them this prompt. It is a braindead question that most children should be able to…
2/3
What do you mean? "B a B" is an intermediate result.
But you're missing the point. It's sufficient for LLM to do just one step. Chaining can be done outside. One step, it can do, even with zero examples. Checkmate, atheists.
One step it can do. With zero examples.
3/3
And note that I did not provide an example. It understands the problem fine, just gets upset by the notation.
A simple puzzle GPTs will NEVER solve:
As a good programmer, I like isolating issues in the simplest form. So, whenever you find yourself trying to explain why GPTs will never reach AGI - just show them this prompt. It is a braindead question that most children should be able to…
2/3
What do you mean? "B a B" is an intermediate result.
But you're missing the point. It's sufficient for LLM to do just one step. Chaining can be done outside. One step, it can do, even with zero examples. Checkmate, atheists.
One step it can do. With zero examples.
3/3
And note that I did not provide an example. It understands the problem fine, just gets upset by the notation.

1/3
I *WAS* WRONG - $10K CLAIMED!
## The Claim
Two days ago, I confidently claimed that "GPTs will NEVER solve the A::B problem". I believed that: 1. GPTs can't truly learn new problems, outside of their training set, 2. GPTs can't perform long-term reasoning, no matter how simple it is. I argued both of these are necessary to invent new science; after all, some math problems take years to solve. If you can't beat a 15yo in any given intellectual task, you're not going to prove the Riemann Hypothesis. To isolate these issues and raise my point, I designed the A::B problem, and posted it here - full definition in the quoted tweet.
## Reception, Clarification and Challenge
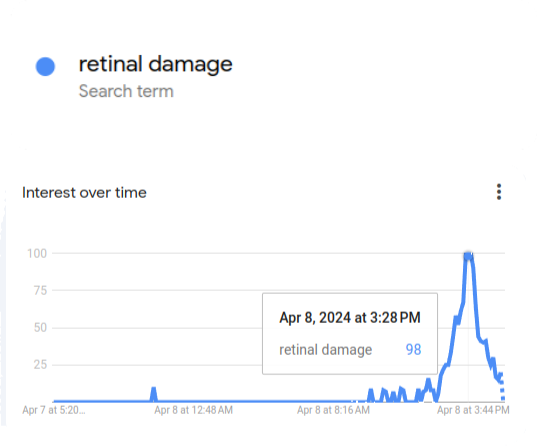
Shortly after posting it, some users provided a solution to a specific 7-token example I listed. I quickly pointed that this wasn't what I meant; that this example was merely illustrative, and that answering one instance isn't the same as solving a problem (and can be easily cheated by prompt manipulation).
So, to make my statement clear, and to put my money where my mouth is, I offered a $10k prize to whoever could design a prompt that solved the A::B problem for *random* 12-token instances, with 90%+ success rate. That's still an easy task, that takes an average of 6 swaps to solve; literally simpler than 3rd grade arithmetic. Yet, I firmly believed no GPT would be able to learn and solve it on-prompt, even for these small instances.
## Solutions and Winner
Hours later, many solutions were submitted. Initially, all failed, barely reaching 10% success rates. I was getting fairly confident, until, later that day,
@ptrschmdtnlsn and
@SardonicSydney
submitted a solution that humbled me. Under their prompt, Claude-3 Opus was able to generalize from a few examples to arbitrary random instances, AND stick to the rules, carrying long computations with almost zero errors. On my run, it achieved a 56% success rate.
Through the day, users
@dontoverfit
(Opus),
@hubertyuan_
(GPT-4),
@JeremyKritz
(Opus) and
@parth007_96
(Opus),
@ptrschmdtnlsn
(Opus) reached similar success rates, and
@reissbaker
made a pretty successful GPT-3.5 fine-tune. But it was only late that night that
@futuristfrog
posted a tweet claiming to have achieved near 100% success rate, by prompting alone. And he was right. On my first run, it scored 47/50, granting him the prize, and completing the challenge.
## How it works!?
The secret to his prompt is... going to remain a secret! That's because he kindly agreed to give 25% of the prize to the most efficient solution. This prompt costs $1+ per inference, so, if you think you can improve on that, you have until next Wednesday to submit your solution in the link below, and compete for the remaining $2.5k! Thanks, Bob.
## How do I stand?
Corrected! My initial claim was absolutely WRONG - for which I apologize. I doubted the GPT architecture would be able to solve certain problems which it, with no margin for doubt, solved. Does that prove GPTs will cure Cancer? No. But it does prove me wrong!
Note there is still a small problem with this: it isn't clear whether Opus is based on the original GPT architecture or not. All GPT-4 versions failed. If Opus turns out to be a new architecture... well, this whole thing would have, ironically, just proven my whole point But, for the sake of the competition, and in all fairness, Opus WAS listed as an option, so, the prize is warranted.
## Who I am and what I'm trying to sell?
Wrong! I won't turn this into an ad. But, yes, if you're new here, I AM building some stuff, and, yes, just like today, I constantly validate my claims to make sure I can deliver on my promises. But that's all I'm gonna say, so, if you're curious, you'll have to find out for yourself (:
####
That's all. Thanks for all who participated, and, again - sorry for being a wrong guy on the internet today! See you.
Gist:
2/3
(The winning prompt will be published Wednesday, as well as the source code for the evaluator itself. Its hash is on the Gist.)
3/3
half of them will be praising Opus (or whatever the current model is) and the other half complaining of CUDA, and 1% boasting about HVM milestones... not sure if that's your type of content, but you're welcome!
I *WAS* WRONG - $10K CLAIMED!
## The Claim
Two days ago, I confidently claimed that "GPTs will NEVER solve the A::B problem". I believed that: 1. GPTs can't truly learn new problems, outside of their training set, 2. GPTs can't perform long-term reasoning, no matter how simple it is. I argued both of these are necessary to invent new science; after all, some math problems take years to solve. If you can't beat a 15yo in any given intellectual task, you're not going to prove the Riemann Hypothesis. To isolate these issues and raise my point, I designed the A::B problem, and posted it here - full definition in the quoted tweet.
## Reception, Clarification and Challenge
Shortly after posting it, some users provided a solution to a specific 7-token example I listed. I quickly pointed that this wasn't what I meant; that this example was merely illustrative, and that answering one instance isn't the same as solving a problem (and can be easily cheated by prompt manipulation).
So, to make my statement clear, and to put my money where my mouth is, I offered a $10k prize to whoever could design a prompt that solved the A::B problem for *random* 12-token instances, with 90%+ success rate. That's still an easy task, that takes an average of 6 swaps to solve; literally simpler than 3rd grade arithmetic. Yet, I firmly believed no GPT would be able to learn and solve it on-prompt, even for these small instances.
## Solutions and Winner
Hours later, many solutions were submitted. Initially, all failed, barely reaching 10% success rates. I was getting fairly confident, until, later that day,
@ptrschmdtnlsn and
@SardonicSydney
submitted a solution that humbled me. Under their prompt, Claude-3 Opus was able to generalize from a few examples to arbitrary random instances, AND stick to the rules, carrying long computations with almost zero errors. On my run, it achieved a 56% success rate.
Through the day, users
@dontoverfit
(Opus),
@hubertyuan_
(GPT-4),
@JeremyKritz
(Opus) and
@parth007_96
(Opus),
@ptrschmdtnlsn
(Opus) reached similar success rates, and
@reissbaker
made a pretty successful GPT-3.5 fine-tune. But it was only late that night that
@futuristfrog
posted a tweet claiming to have achieved near 100% success rate, by prompting alone. And he was right. On my first run, it scored 47/50, granting him the prize, and completing the challenge.
## How it works!?
The secret to his prompt is... going to remain a secret! That's because he kindly agreed to give 25% of the prize to the most efficient solution. This prompt costs $1+ per inference, so, if you think you can improve on that, you have until next Wednesday to submit your solution in the link below, and compete for the remaining $2.5k! Thanks, Bob.
## How do I stand?
Corrected! My initial claim was absolutely WRONG - for which I apologize. I doubted the GPT architecture would be able to solve certain problems which it, with no margin for doubt, solved. Does that prove GPTs will cure Cancer? No. But it does prove me wrong!
Note there is still a small problem with this: it isn't clear whether Opus is based on the original GPT architecture or not. All GPT-4 versions failed. If Opus turns out to be a new architecture... well, this whole thing would have, ironically, just proven my whole point But, for the sake of the competition, and in all fairness, Opus WAS listed as an option, so, the prize is warranted.
## Who I am and what I'm trying to sell?
Wrong! I won't turn this into an ad. But, yes, if you're new here, I AM building some stuff, and, yes, just like today, I constantly validate my claims to make sure I can deliver on my promises. But that's all I'm gonna say, so, if you're curious, you'll have to find out for yourself (:
####
That's all. Thanks for all who participated, and, again - sorry for being a wrong guy on the internet today! See you.
Gist:
2/3
(The winning prompt will be published Wednesday, as well as the source code for the evaluator itself. Its hash is on the Gist.)
3/3
half of them will be praising Opus (or whatever the current model is) and the other half complaining of CUDA, and 1% boasting about HVM milestones... not sure if that's your type of content, but you're welcome!
Last edited:
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a...
Computer Science > Computation and Language
[Submitted on 10 Apr 2024]Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth GopalThis work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
| Comments: | 9 pages, 4 figures, 4 tables |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Neural and Evolutionary Computing (cs.NE) |
| Cite as: | arXiv:2404.07143 [cs.CL] |
| (or arXiv:2404.07143v1 [cs.CL] for this version) | |
| [2404.07143] Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention Focus to learn more |
Submission history
From: Tsendsuren Munkhdalai [view email][v1] Wed, 10 Apr 2024 16:18:42 UTC (248 KB)
Last edited:
1/1
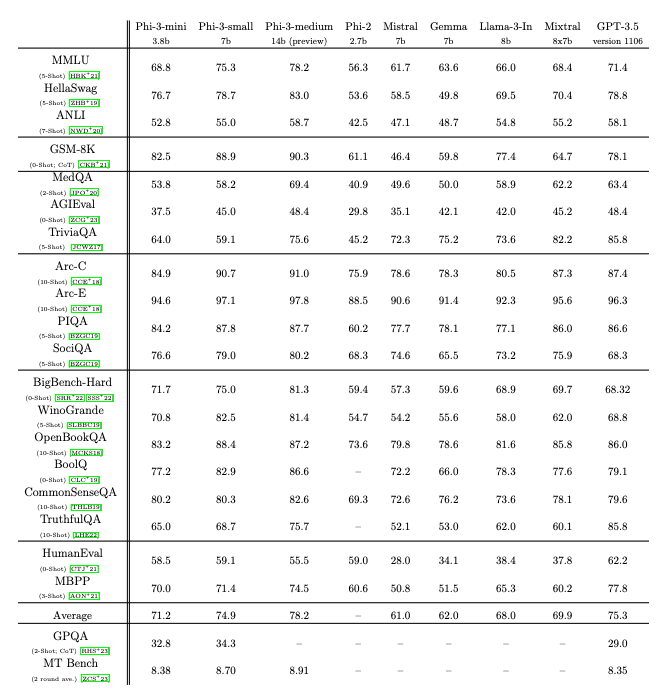
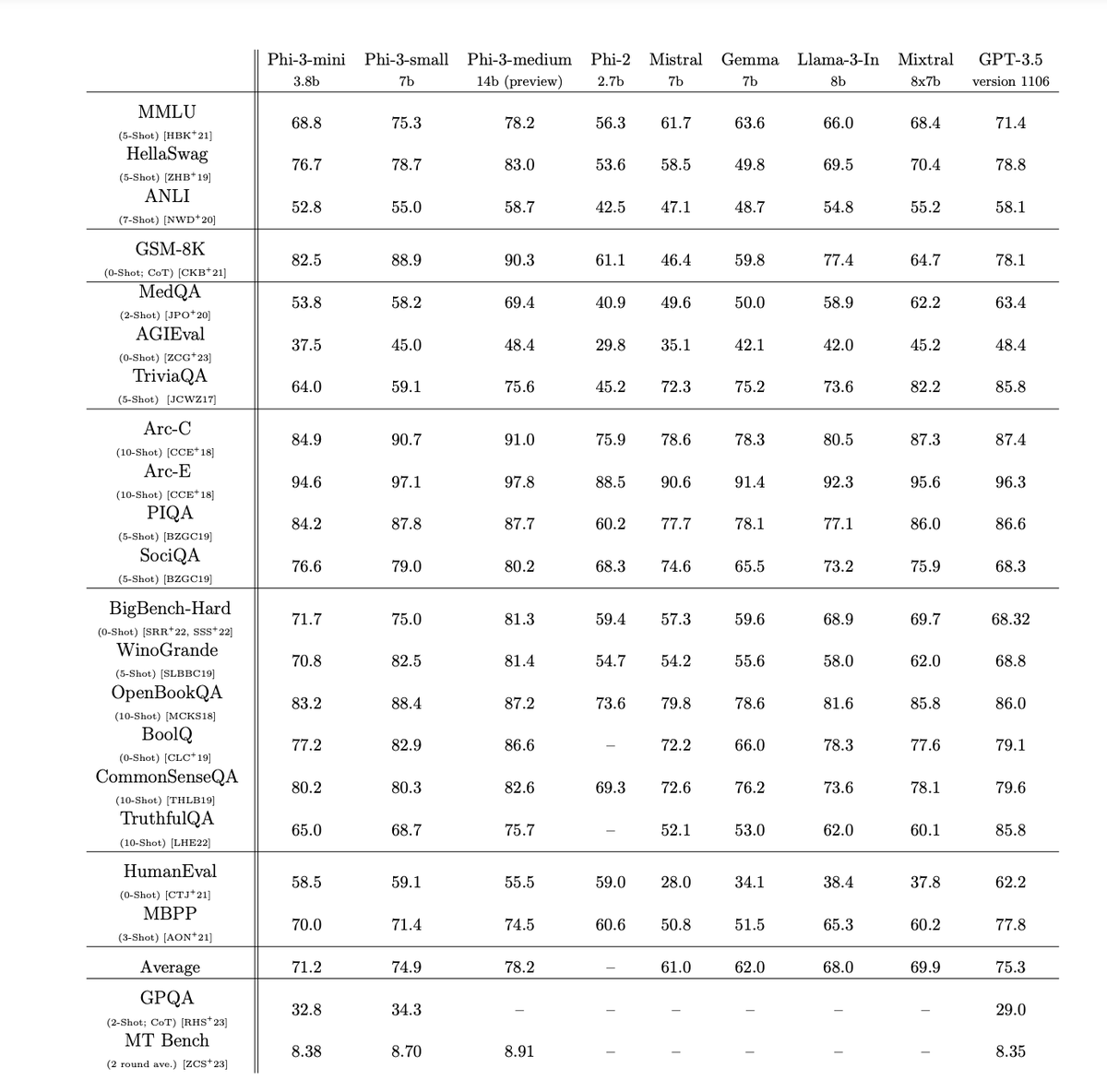
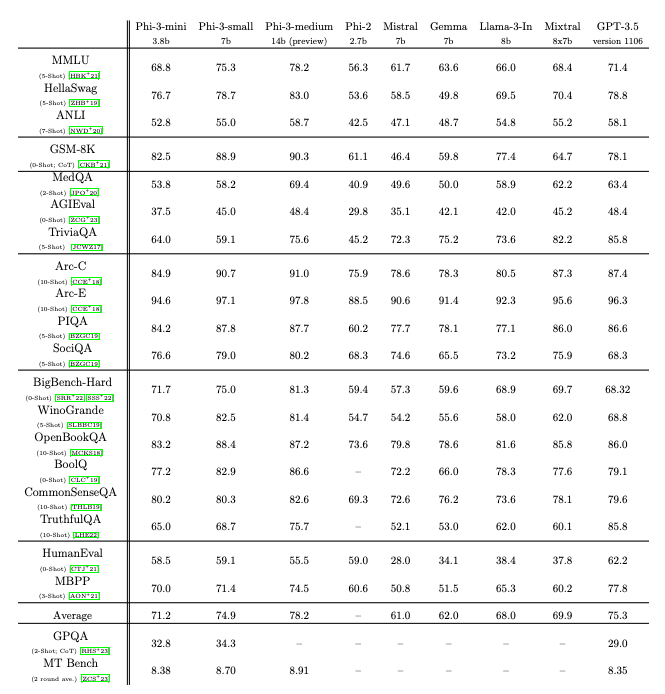
phi-3-mini: 3.8B model matching Mixtral 8x7B and GPT-3.5
Plus a 7B model that matches Llama 3 8B in many benchmarks.
Plus a 14B model.
 arxiv.org
arxiv.org
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
phi-3-mini: 3.8B model matching Mixtral 8x7B and GPT-3.5
Plus a 7B model that matches Llama 3 8B in many benchmarks.
Plus a 14B model.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on...
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

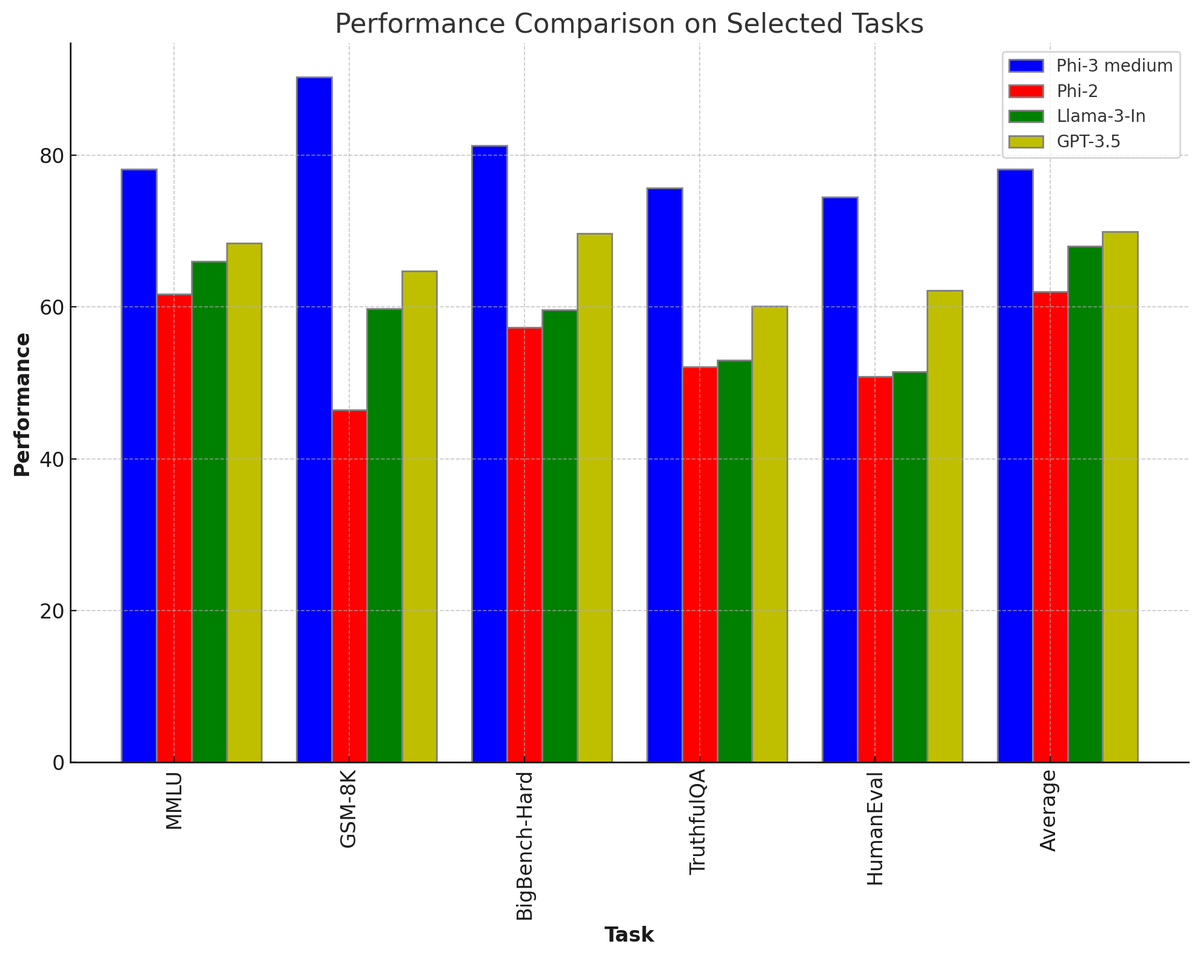
1/5
Microsoft just released Phi-3
Phi-3 14B beats Llama-3 8B, GPt-3.5 and Mixtral 8x7b MoE in most of the benchmarks.
Even the Phi-3 mini beats Llama-3 8B in MMLU and HellaSwag.
2/5
More details and insights to follow in tomorrow's AI newsletter.
Subscribe now to get it delivered to your inbox first thing in the morning tomorrow: Unwind AI | Shubham Saboo | Substack
3/5
Reaserch Paper:
4/5
This is absolutely insane speed of Opensource AI development.
5/5
True, all of this is happening so fast!!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Microsoft just released Phi-3
Phi-3 14B beats Llama-3 8B, GPt-3.5 and Mixtral 8x7b MoE in most of the benchmarks.
Even the Phi-3 mini beats Llama-3 8B in MMLU and HellaSwag.
2/5
More details and insights to follow in tomorrow's AI newsletter.
Subscribe now to get it delivered to your inbox first thing in the morning tomorrow: Unwind AI | Shubham Saboo | Substack
3/5
Reaserch Paper:
4/5
This is absolutely insane speed of Opensource AI development.
5/5
True, all of this is happening so fast!!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
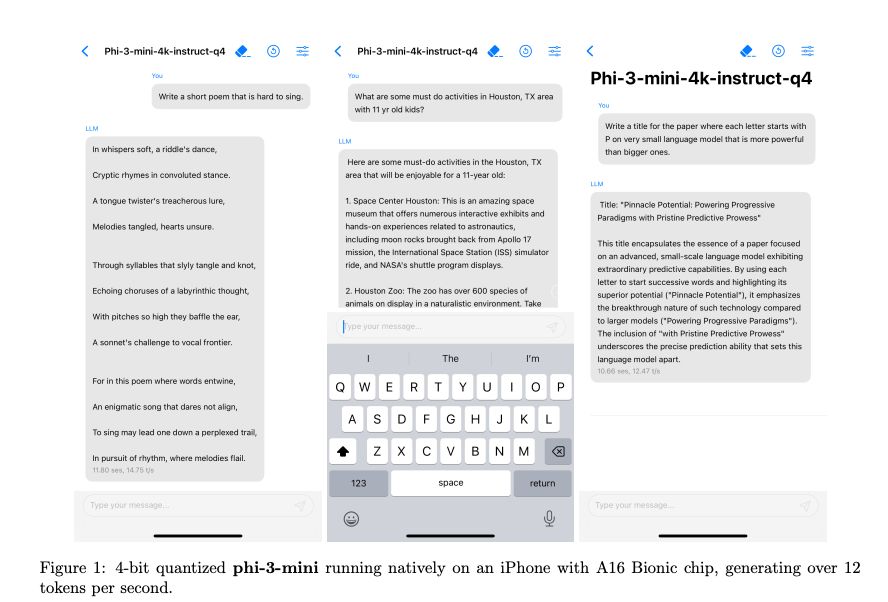
1/2
phi-3 is out! never would have guessed that our speculative attempt at creating synthetic python code for phi-1 (following TinyStories) would eventually lead to a gpt-3.5-level SLM. defly addicted to generating synth data by now...
2/2
hf:
phi-3 is out! never would have guessed that our speculative attempt at creating synthetic python code for phi-1 (following TinyStories) would eventually lead to a gpt-3.5-level SLM. defly addicted to generating synth data by now...
2/2
hf:
https://langfuse.datastrain.io/project/cluve1io10001y0rnqesj5bz4/traces/484ec288-6a9d-480b-bcca-9c8dfd965325?observation=b86ac62c-9ac2-40d2-9916-63e4c3e11b17…
@Prince_Canuma
mlx-community (MLX Community)
@answerdotai
@AIatMeta
@huggingface
@MicrosoftAI
microsoft/Phi-3-mini-4k-instruct · Hugging Face
@Prince_Canuma
mlx-community (MLX Community)
@answerdotai
@AIatMeta
@huggingface
@MicrosoftAI
microsoft/Phi-3-mini-4k-instruct · Hugging Face
1/5
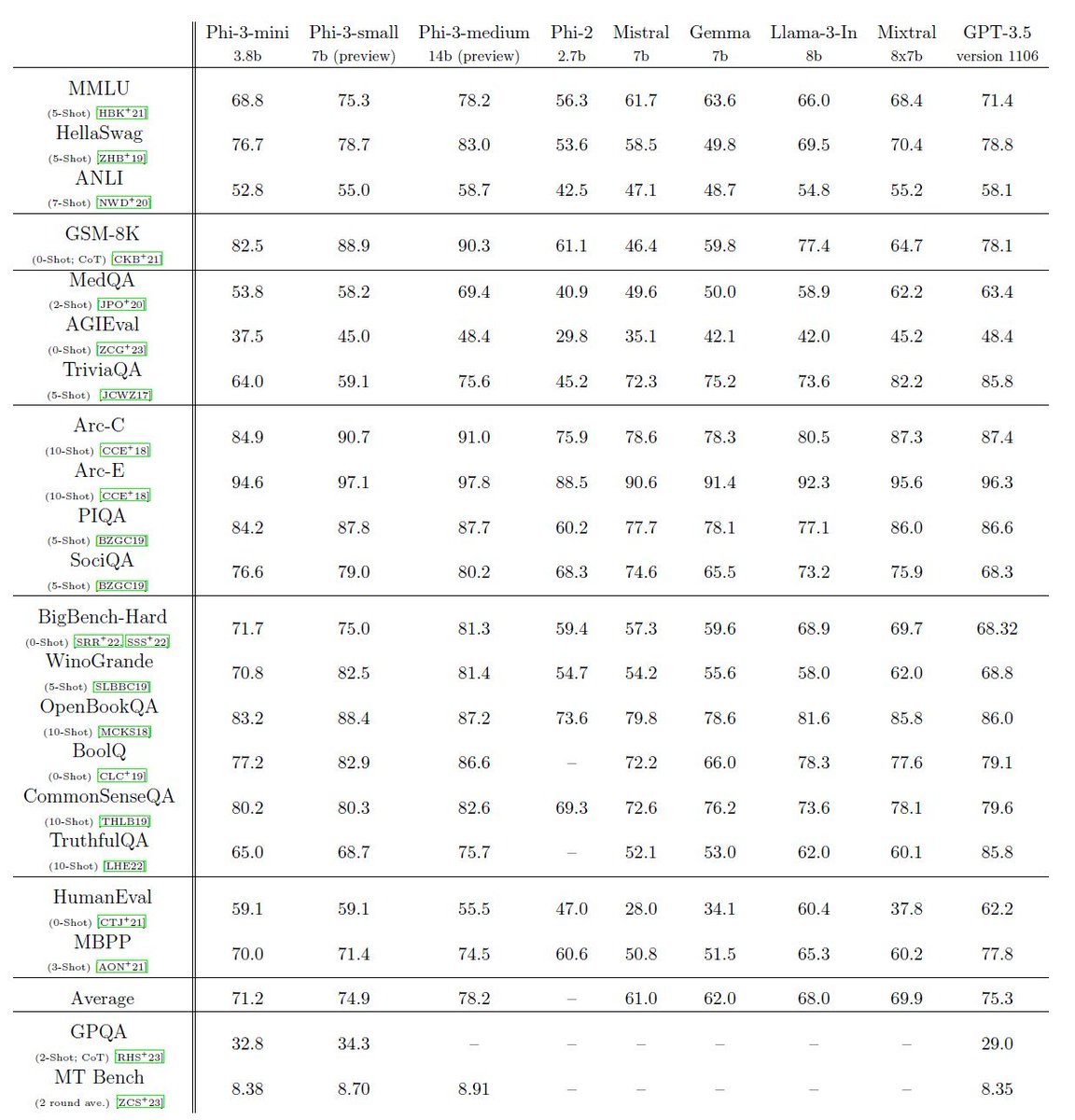
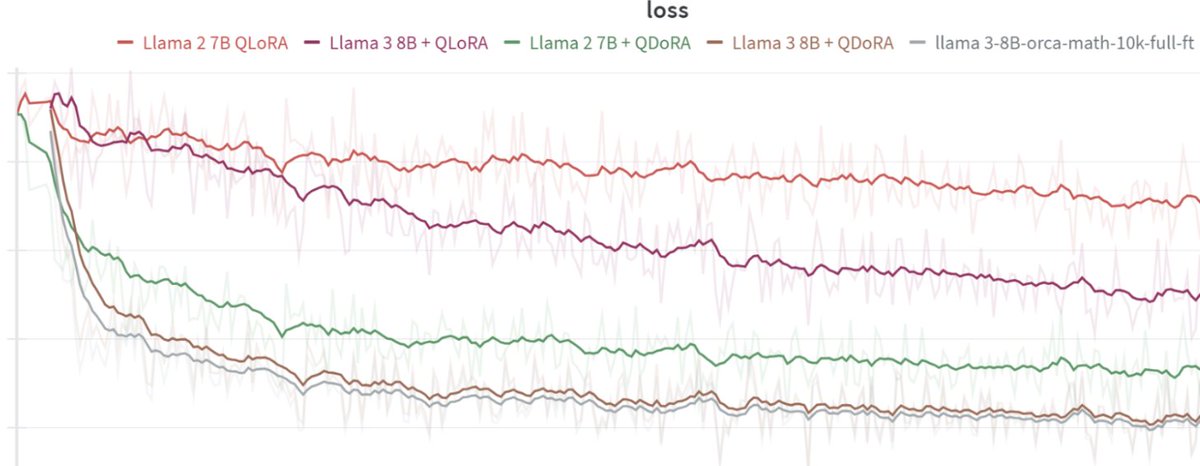
Amazing numbers. Phi-3 is topping GPT-3.5 on MMLU at 14B. Trained on 3.3 trillion tokens. They say in the paper 'The innovation lies entirely in our dataset for training - composed of heavily filtered web data and synthetic data.'
2/5
Small is so big right now!
3/5
phi-3-mini: 3.8B model matching Mixtral 8x7B and GPT-3.5
Plus a 7B model that matches Llama 3 8B in many benchmarks.
Plus a 14B model.
[2404.14219] Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
4/5
The prophecy has been fulfilled!
5/5
Wow.
'Phi-3-mini can be quantized to 4-bits so that it only occupies ≈ 1.8GB of memory. We tested the quantized model by deploying phi-3-mini on iPhone 14 with A16 Bionic chip running natively on-device and fully offline achieving more than 12 tokens per second.'
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Amazing numbers. Phi-3 is topping GPT-3.5 on MMLU at 14B. Trained on 3.3 trillion tokens. They say in the paper 'The innovation lies entirely in our dataset for training - composed of heavily filtered web data and synthetic data.'
2/5
Small is so big right now!
3/5
phi-3-mini: 3.8B model matching Mixtral 8x7B and GPT-3.5
Plus a 7B model that matches Llama 3 8B in many benchmarks.
Plus a 14B model.
[2404.14219] Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
4/5
The prophecy has been fulfilled!
5/5
Wow.
'Phi-3-mini can be quantized to 4-bits so that it only occupies ≈ 1.8GB of memory. We tested the quantized model by deploying phi-3-mini on iPhone 14 with A16 Bionic chip running natively on-device and fully offline achieving more than 12 tokens per second.'
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

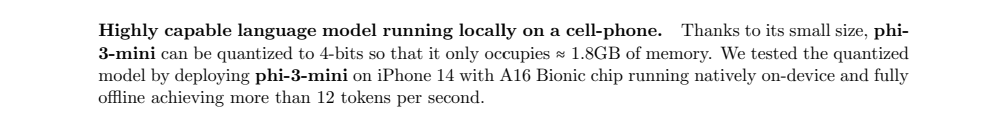
1/9
Run Microsoft Phi-3 locally in 3 simple steps (100% free and without internet):
2/9
1. Install Ollama on your Desktop
- Go to https://ollama.com/ - Download Ollama on your computer (works on Mac, Windows and Linux)
- Open the terminal and type this command: 'ollama run phi3'
3/9
2. Install OpenWeb UI (ChatGPT like opensource UI)
- Go to https://docs.openwebui.com - Install the docker image of Open Web UI with a single command
- Make sure Docker is installed and running on your computer
4/9
3. Run the model locally like ChatGPT
- Open the ChatGPT like UI locally by going to this link: http://localhost:3000 - Select the model from the top.
- Query and ask questions like ChatGPT
This is running on Macbook M1 Pro 16GB machine.
5/9
If you find this useful, RT to share it with your friends.
Don't forget to follow me
@Saboo_Shubham_ for more such LLMs tips and resources.
6/9
Run Microsoft Phi-3 locally in 3 simple steps (100% free and without internet):
7/9
Not checked yet.
@ollama was the first to push the updates!
8/9
That would be fine-tuning. You can try out
@monsterapis for nocode finetuning of LLMs.
9/9
Series of language models that pretty much outperformed llama-3 even with the small size.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Run Microsoft Phi-3 locally in 3 simple steps (100% free and without internet):
2/9
1. Install Ollama on your Desktop
- Go to https://ollama.com/ - Download Ollama on your computer (works on Mac, Windows and Linux)
- Open the terminal and type this command: 'ollama run phi3'
3/9
2. Install OpenWeb UI (ChatGPT like opensource UI)
- Go to https://docs.openwebui.com - Install the docker image of Open Web UI with a single command
- Make sure Docker is installed and running on your computer
4/9
3. Run the model locally like ChatGPT
- Open the ChatGPT like UI locally by going to this link: http://localhost:3000 - Select the model from the top.
- Query and ask questions like ChatGPT
This is running on Macbook M1 Pro 16GB machine.
5/9
If you find this useful, RT to share it with your friends.
Don't forget to follow me
@Saboo_Shubham_ for more such LLMs tips and resources.
6/9
Run Microsoft Phi-3 locally in 3 simple steps (100% free and without internet):
7/9
Not checked yet.
@ollama was the first to push the updates!
8/9
That would be fine-tuning. You can try out
@monsterapis for nocode finetuning of LLMs.
9/9
Series of language models that pretty much outperformed llama-3 even with the small size.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


microsoft/Phi-3-mini-4k-instruct · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
Edit: All versions: Phi-3 - a microsoft Collection
1/4
Nat Friedman says there will be a surge of new discoveries as AI digests the entire scientific literature and identifies connections that haven't been noticed before
2/4
Source:
3/4
it sounds pretty amazing
4/4
ikr
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Nat Friedman says there will be a surge of new discoveries as AI digests the entire scientific literature and identifies connections that haven't been noticed before
2/4
Source:
3/4
it sounds pretty amazing
4/4
ikr
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

OpenAI CEO Sam Altman says GPT-4 is the dumbest AI model you'll ever have to use again
According to OpenAI CEO Sam Altman, GPT-4 is by far the dumbest AI model that humans have to use compared to what's coming in the future.
 the-decoder.com
the-decoder.com
May 2, 2024
OpenAI CEO Sam Altman says GPT-4 is the dumbest AI model you'll ever have to use again
YouTube Screenshot via Stanford eCorner
Matthias Bastian
Online journalist Matthias is the co-founder and publisher of THE DECODER. He believes that artificial intelligence will fundamentally change the relationship between humans and computers.
Profile
According to OpenAI CEO Sam Altman, GPT-4 is by far the dumbest AI model that humans have to use compared to what's coming in the future.
During a recent appearance at Stanford University, Altman said that OpenAI's current AI models still have significant room for improvement. " ChatGPT is like mildly embarrassing at best. GPT-4 is by far the dumbest model any of you will ever ever have to use again," he said during an appearance at Stanford University.
The CEO believes that there will be much more powerful AI systems in the coming years, saying with a high degree of scientific certainty that humanity will have more advanced models every year.
"GPT-5 is going to be a lot smarter than GPT-4, GPT-6 is going to be a lot smarter than GPT-5, and we are not near the top of this curve," Altman said.
Developing such systems is expensive, but that doesn't worry Altman. "Whether we burn 500 million a year or 5 billion or 50 billion a year, I don't care. I genuinely don't, as long as we can, I think, stay on a trajectory where eventually we create way more value for society than that, and as long as we can figure out a way to pay the bills. We're making AGI, it's going to be expensive, it's totally worth it," he said.
External media content ( www.youtube.com) has been blocked here. When loading or playing, connections are established to the servers of the respective providers. Personal data may be communicated to the providers in the process. You can find more information in our privacy policy.
Agents as the next evolution of AI
While Altman didn't provide a timeline for the development of artificial general intelligence (AGI), he told MIT Technology Review that he believes there will be several versions of AGI that are more or less suitable for certain tasks.Altman sees intelligent agents as the killer application for future AI systems. These "super-competent colleagues" would know everything about a person's life, including emails and conversations, and could perform certain tasks on the fly, suggest solutions to complex problems, and ask questions when needed.
In the future, Altman believes that AI will not only generate better text, images, and video, but will also be able to perform real-world tasks, further integrating systems into people's daily lives.
According to Altman, this doesn't necessarily require new hardware, as the AI assistant could exist in the cloud - though many users would likely prefer a new device for it.
Altman is reportedly working with iPhone designer Jony Ive on new AI hardware, and OpenAI is said to be developing two agent systems that will automate entire work processes.
GPT-5 is reportedly in development and could be released as early as mid-year. It is expected to be significantly better than its predecessor, GPT-4. It is rumored that GPT-5 will support video generation in addition to text and images. If OpenAI follows the DALL-E approach with its AI video generator Sora, video generation could be integrated into ChatGPT.
Summary
- OpenAI CEO Sam Altman expects much more powerful AI models than GPT-4 in the future. In his opinion, GPT-4 is "by far the dumbest model" compared to what is yet to come.
- Altman sees intelligent agents as the killer application for future AI systems. They will act as "super-competent colleagues" who know everything about a person's life and can perform specific tasks or suggest solutions to more complex problems.
- GPT-5 is already under development and will be released by the middle of this year at the earliest. It is said to be much better than GPT-4. Rumor has it that GPT-5 will support video as well as text and images.
 That's like Apple saying that their latest iPhone will be the weakest iPhone and that all future versions will be more powerful. No shyt, that's how technology works
That's like Apple saying that their latest iPhone will be the weakest iPhone and that all future versions will be more powerful. No shyt, that's how technology worksShould we slow down AI research? | Debate with Meta, IBM, FHI, FLI
Future of Life Institute
Subscribe | 68.5K
Shared May 7, 2024
Mark Brakel (FLI Director of Policy), Yann LeCun, Francesca Rossi, and Nick Bostrom debate: "Should we slow down research on AI?" at the World AI Cannes Festival in February 2024.
1/2
This demo is insane.
A student shares their iPad screen with the new ChatGPT + GPT-4o, and the AI speaks with them and helps them learn in *realtime*.
Imagine giving this to every student in the world.
The future is so, so bright.
2/2
From 3 days ago.
For many, this OpenAI update will be “THE” way that they learn with an AI tutor.
Magic.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
This demo is insane.
A student shares their iPad screen with the new ChatGPT + GPT-4o, and the AI speaks with them and helps them learn in *realtime*.
Imagine giving this to every student in the world.
The future is so, so bright.
2/2
From 3 days ago.
For many, this OpenAI update will be “THE” way that they learn with an AI tutor.
Magic.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
Bugün tanıtılan GPT-4o ile simultane çevirinin ruhuna El-Fatiha diyebiliriz.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Bugün tanıtılan GPT-4o ile simultane çevirinin ruhuna El-Fatiha diyebiliriz.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/4
Introducing GPT-4o, our new model which can reason across text, audio, and video in real time.
It's extremely versatile, fun to play with, and is a step towards a much more natural form of human-computer interaction (and even human-computer-computer interaction):
2/4
The new Voice Mode will be coming to ChatGPT Plus in upcoming weeks.
3/4
GPT-4o can also generate any combination of audio, text, and image outputs, which leads to interesting new capabilities we are still exploring.
See e.g. the "Explorations of capabilities" section in our launch blog post (https://openai.com/index/hello-gpt-4o/…), or these generated images:
4/4
We also have significantly improved non-English language performance quite a lot, including improving the tokenizer to better compress many of them:
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Introducing GPT-4o, our new model which can reason across text, audio, and video in real time.
It's extremely versatile, fun to play with, and is a step towards a much more natural form of human-computer interaction (and even human-computer-computer interaction):
2/4
The new Voice Mode will be coming to ChatGPT Plus in upcoming weeks.
3/4
GPT-4o can also generate any combination of audio, text, and image outputs, which leads to interesting new capabilities we are still exploring.
See e.g. the "Explorations of capabilities" section in our launch blog post (https://openai.com/index/hello-gpt-4o/…), or these generated images:
4/4
We also have significantly improved non-English language performance quite a lot, including improving the tokenizer to better compress many of them:
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




1/1
OpenAI just announced "GPT-4o". It can reason with voice, vision, and text.
The model is 2x faster, 50% cheaper, and has 5x higher rate limit than GPT-4 Turbo.
It will be available for free users and via the API.
The voice model can even pick up on emotion and generate emotive voice.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
OpenAI just announced "GPT-4o". It can reason with voice, vision, and text.
The model is 2x faster, 50% cheaper, and has 5x higher rate limit than GPT-4 Turbo.
It will be available for free users and via the API.
The voice model can even pick up on emotion and generate emotive voice.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Jean Jacket
NOPE
I already got a ticket...already got a ticket to Funkmaster Flex Night