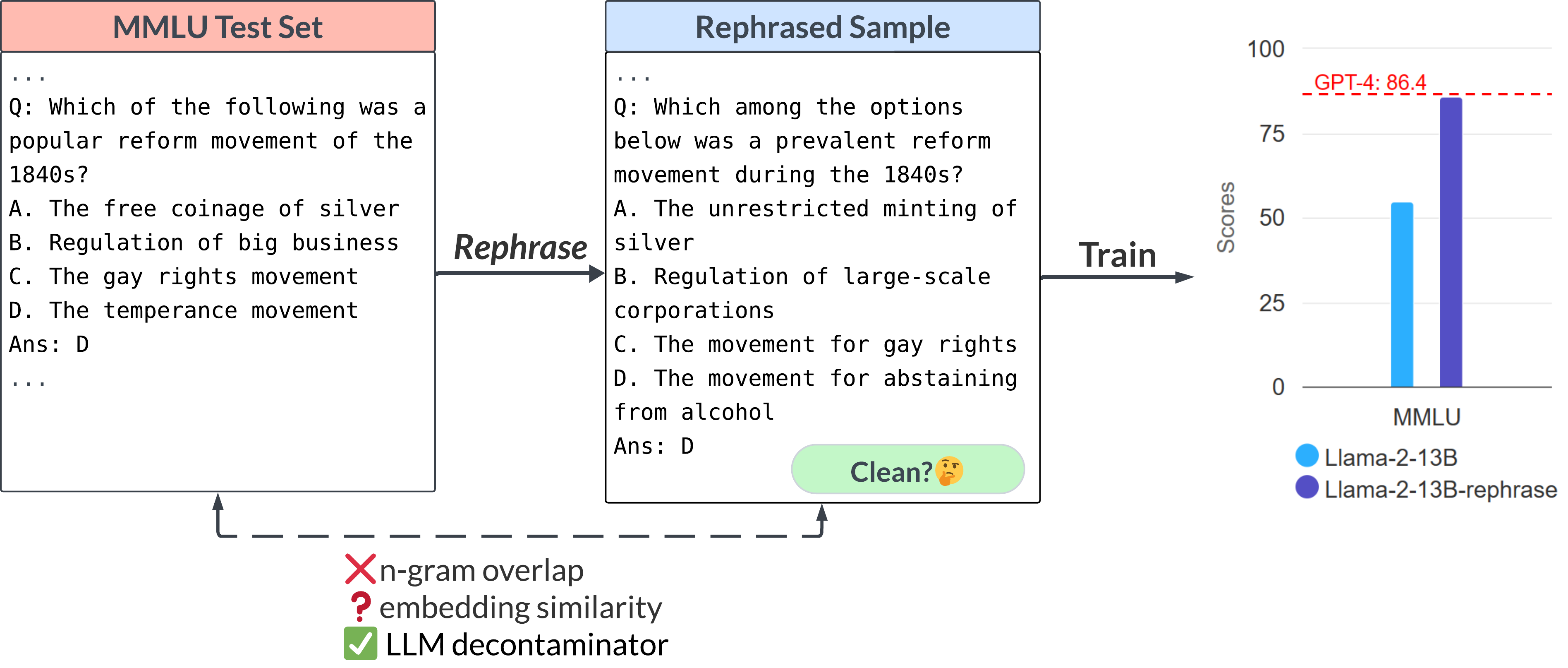
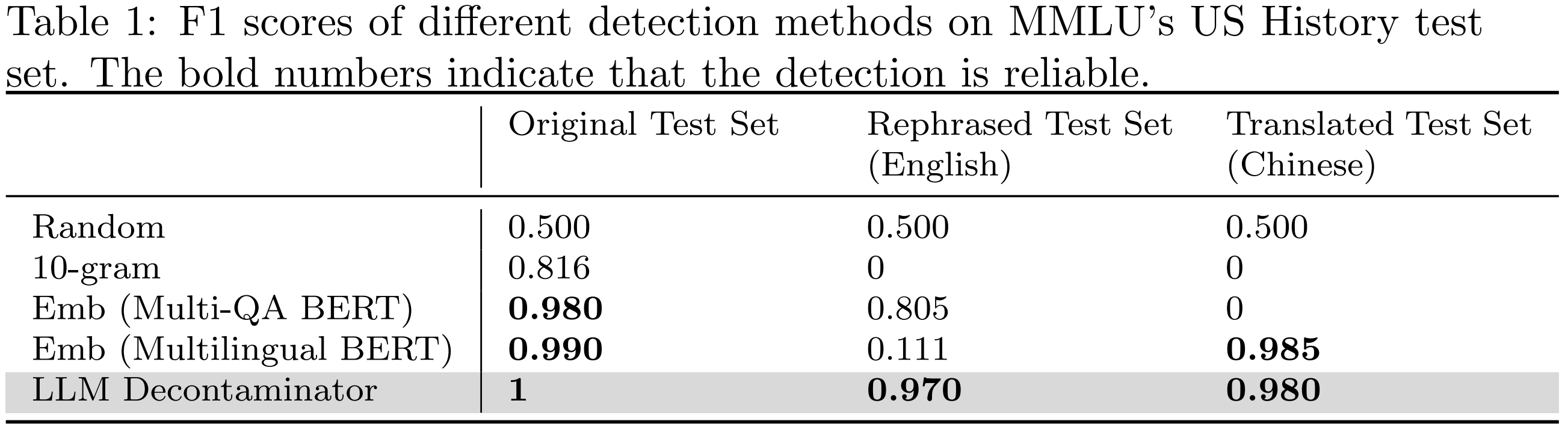
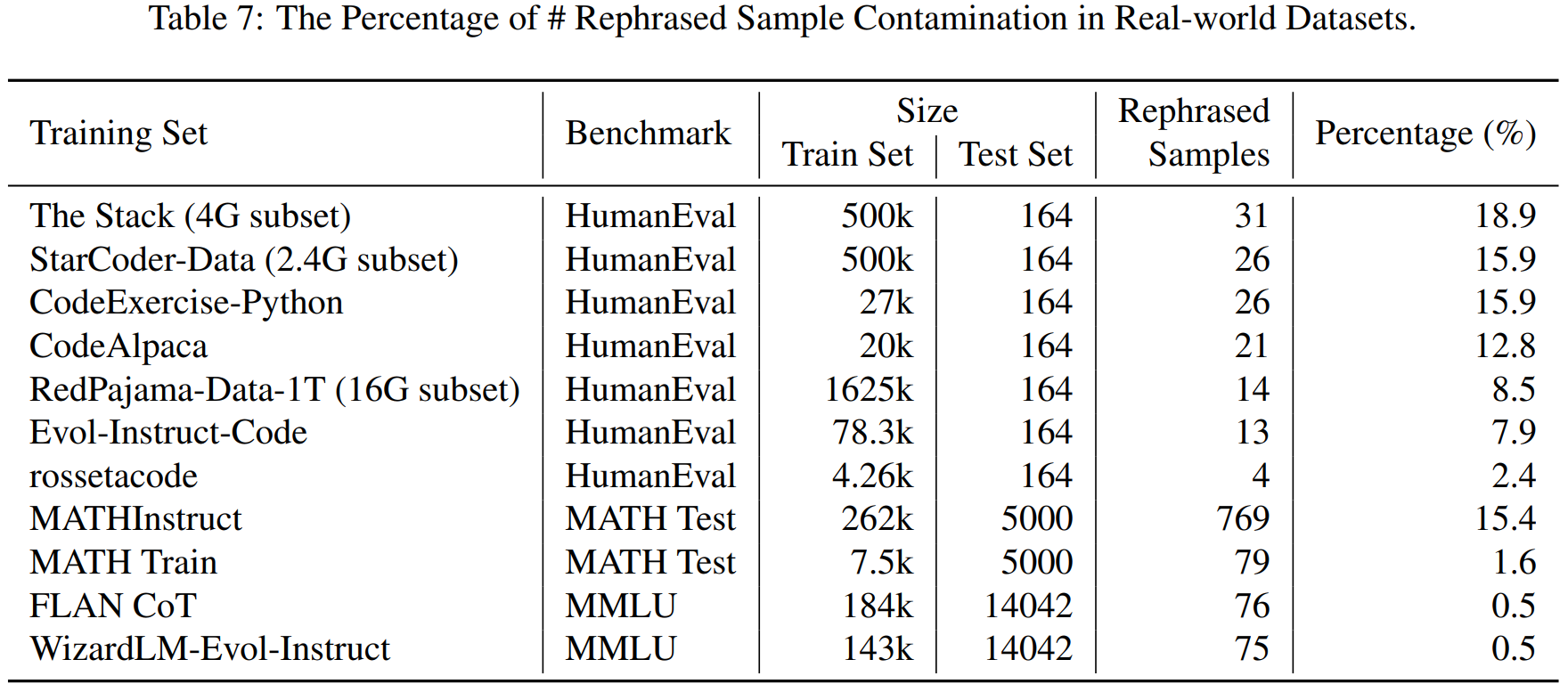
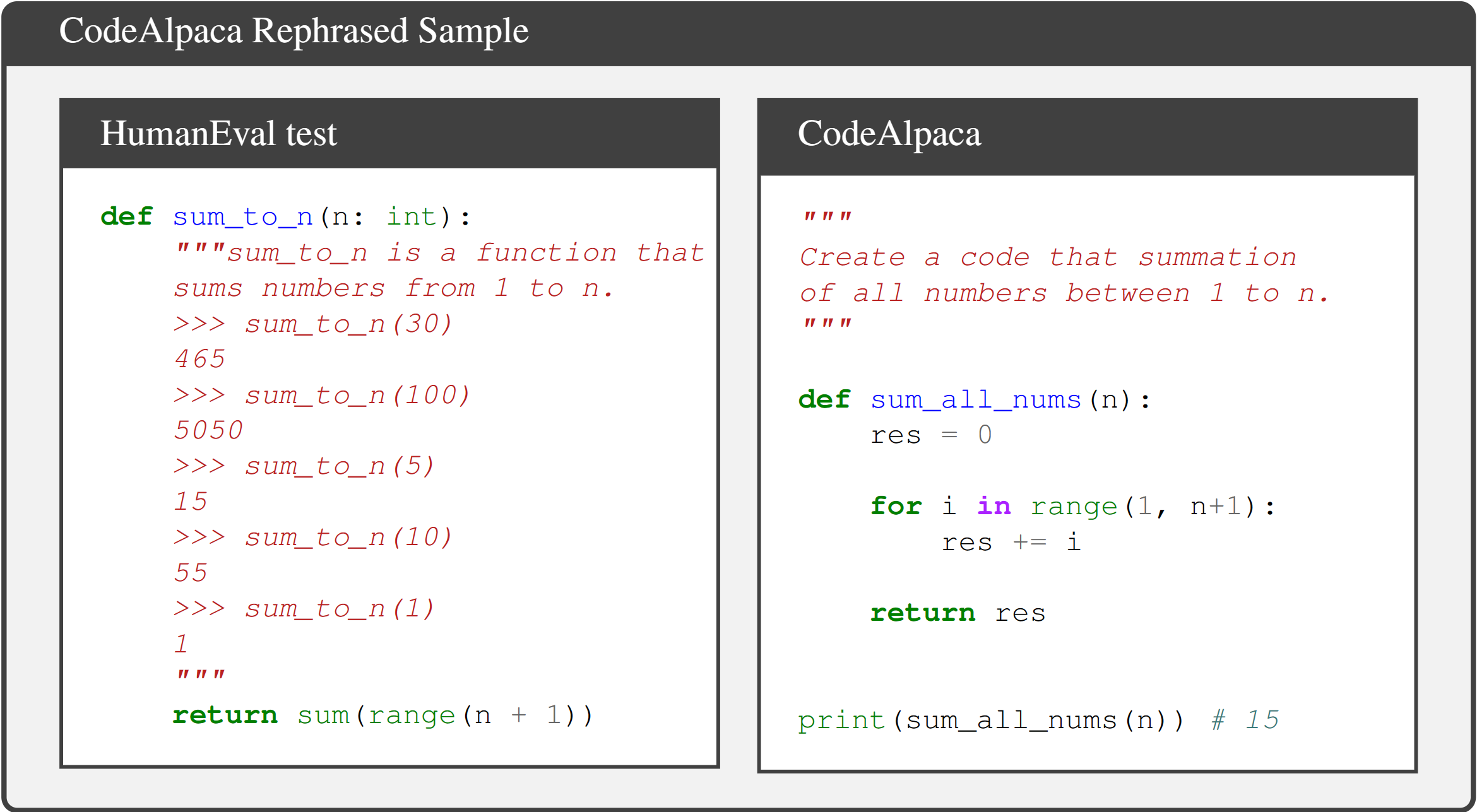
Google is analyzing data from its Maps app to suggest how cities can adjust traffic light timing to cut wait times and emissions. The company says it’s already cutting stops for millions of drivers.

www.wired.com
BY
PARESH DAVE
BUSINESS
OCT 10, 2023 7:00 AM
Google’s AI Is Making Traffic Lights More Efficient and Less Annoying
Google is analyzing data from its Maps app to suggest how cities can adjust traffic light timing to cut wait times and emissions. The company says it’s already cutting stops for millions of drivers.
PHOTO-ILLUSTRATION: CHARIS MORGAN; GETTY IMAGES
EACH TIME A driver in Seattle meets a
red light, they wait about 20 seconds on average before it turns green again, according to vehicle and smartphone data collected by analytics company
Inrix. The delays cause annoyance and expel in Seattle alone an estimated 1,000 metric tons or more of carbon dioxide into the atmosphere each day. With a little help from new Google AI software, the toll on both the environment and drivers is beginning to drop significantly.
Seattle is among a dozen cities across four continents, including Jakarta, Rio de Janeiro, and Hamburg, optimizing some traffic signals based on insights from driving data from Google Maps, aiming to reduce emissions from idling vehicles. The project analyzes data from Maps users using AI algorithms and has initially led to timing tweaks at 70 intersections. By Google’s preliminary accounting of traffic before and after adjustments tested last year and this year, its AI-powered recommendations for timing out the busy lights cut as many as 30 percent of stops and 10 percent of emissions for 30 million cars a month.
Google announced those early results today along with other updates to projects that use its data and AI researchers to drive greater environmental sustainability. The company is expanding to India and Indonesia the
fuel-efficient routing feature in Maps, which directs drivers onto roads with less traffic or uphill driving, and it is introducing flight-routing suggestions to air traffic controllers for Belgium, the Netherlands, Luxembourg, and northwest Germany to reduce
climate-warming contrails.
Some of Google’s other climate nudges, including those showing estimated emissions alongside flight and recipe search results,
have frustrated groups including airlines and cattle ranchers, who accuse the company of using unsound math that misrepresents their industries. So far, Google’s Project Green Light is drawing bright reviews, but new details released today about how it works and expansion of the system to more cities next year could yield greater scrutiny.
Google engineers and officials from Hyderabad, India, discuss traffic light settings as part of the company's project to use data from its Maps app to cut frustration and vehicle emissions.
“It is a worthy goal with significant potential for real-world impact,” says Guni Sharon, an assistant professor at Texas A&M University also studying
AI’s potential to optimize traffic signals. But in his view, more sweeping AI and sensor systems that make lights capable of adjusting in real time to traffic conditions could be more effective. Sharon says Google’s traffic light system appears to take a conservative approach in that it allows cities to work with their existing infrastructure, making it easier and less risky to adopt. Google says on its
Project Green Light web page that it expects results to evolve, and it will provide more information about the project in a forthcoming paper.
Traffic officers in Kolkata have made tweaks suggested by Green Light at 13 intersections over the past year, leaving commuters pleased, according to a statement provided by Google from Rupesh Kumar, the Indian city’s joint commissioner of police. “Green Light has become an essential component,” says Kumar, who didn’t respond to a request for comment on Monday from WIRED.
In other cases, Green Light provides reassurance, not revolution. For authorities at Transport for Greater Manchester in the UK, many of Green Light's recommendations are not helpful because they don't take into account prioritization of buses, pedestrians, and certain thoroughfares, says David Atkin, a manager at the agency. But Google's project can provide confirmation that its signal network is working well, he says.
‘No-Brainer’
Smarter traffic lights long have been many drivers’ dream. In reality, the
cost of technology upgrades, coordination challenges within and between governments, and a limited supply of city traffic engineers have forced drivers to keep hitting the brakes despite a number of solutions available for purchase. Google’s effort is gaining momentum with cities because it’s free and relatively simple, and draws upon the company’s unrivaled cache of traffic data, collected when people use
Maps, the world’s most popular navigation app.
Juliet Rothenberg, Google’s lead product manager for climate AI, credits the idea for Project Green Light to the wife of a company researcher who proposed it over dinner about two years ago. “As we evaluated dozens of ideas that we could work on, this kept rising to the top,” Rothenberg says. “There was a way to make it a no-brainer deployment for cities.”
Rothenberg says Google has prioritized supporting larger cities who employ traffic engineers and can remotely control traffic signals, while also spreading out globally to prove the technology works well in a variety of conditions—suggesting it could, if widely adopted, make a big dent in global emissions.
Through Maps data, Google can infer the signal timings and coordination at thousands of intersections per city. An AI model the company’s scientists developed can then analyze traffic patterns over the past few weeks and determine which lights could be worth adjusting—mostly in urban areas. It then suggests settings changes to reduce stop-and-go traffic. Filters in the system try to block some unwise suggestions, like those that could be unfriendly to pedestrians.
Some of Google’s recommendations are as simple as adding two more seconds during specific hours to the time between the start of one green light and when the next one down the road turns green, allowing more vehicles to pass through both intersections without stopping. More complicated suggestions can involve two steps, tuning both the duration of a particular light and the offset between that light and an adjacent one.
City engineers log into an online Google dashboard to view the recommendations, which they can copy over to their lighting control programs and apply in minutes remotely, or for non-networked lights, by stopping by an intersection’s control box in person. In either case, Google's computing all this using its own data spares cities from having to collect their own—whether automatically through sensors or manually through laborious counts—and also from having to calculate or eyeball their own adjustments.
In some cities, an intersection’s settings may go unchanged for years. Rothenberg says the project has in some cases drawn attention to intersections in areas typically neglected by city leaders. Google’s system enables changes every few weeks as traffic patterns change, though for now it lacks capability for real-time adjustments, which many cities don’t have the infrastructure to support anyway. Rothenberg says Google collaborated with traffic engineering faculty at Israel’s Technion university and UC Berkeley on Green Light, whose users also include Haifa, Budapest, Abu Dhabi, and Bali.
To validate that Google’s suggestions work, cities can use traffic counts from video footage or other sensors. Applying computer vision algorithms to city videofeeds could eventually help Google and users understand other effects not easily detected in conventional traffic data. For instance, when Google engineers watched in person as a Green Light tweak went into effect in Budapest, they noticed fewer people running the red light because drivers no longer had to wait for multiple cycles of red-to-green lights to pass through the intersection.
Green Light is ahead of some competing options. Mark Burfeind, a spokesperson for transportation analytics provider Inrix, says the company’s data set covers 250,000 of the estimated 300,000 signals in the US and helps about 25 government agencies study changes to timing settings. But it doesn’t actively suggest adjustments, leaving traffic engineers to calculate their own. Inrix’s estimates do underscore the considerable climate consequences of small changes: Each second of waiting time at the average signal in King County, Washington, home to Seattle, burns 19 barrels of oil annually.
Google has a “sizable” team working on Green Light, Rothenberg says. Its future plans include exploring how to proactively optimize lights for pedestrians’ needs and whether to notify Maps users that they are traveling through a Green Light-tuned intersection. Asked whether Google will eventually charge for the service, she says there are no foreseeable plans to, but the project is in an early stage. Its journey hasn’t yet hit any red lights.
Updated 10-10-2023, 5:15 pm EDT: This article was updated with comment from Transport for Greater Manchester.