The SAM 2 architecture can be seen as a generalization of SAM from the image to the video domain. SAM 2 can be prompted by clicks (positive or negative), bounding boxes, or masks to define the extent of the object in a given frame. A lightweight mask decoder takes an image embedding for the current frame and encoded prompts to output a segmentation mask for the frame. In the video setting, SAM 2 propagates this mask prediction to all video frames to generate a masklet. Prompts can then be iteratively added on any subsequent frame to refine the masklet prediction.
To predict masks accurately across all video frames, we introduce a memory mechanism consisting of a memory encoder, a memory bank, and a memory attention module. When applied to images, the memory components are empty and the model behaves like SAM. For video, the memory components enable storing information about the object and previous user interactions in that session, allowing SAM 2 to generate masklet predictions throughout the video. If there are additional prompts provided on other frames, SAM 2 can effectively correct its predictions based on the stored memory context of the object.
Memories of frames are created by the memory encoder based on the current mask prediction and placed in the memory bank for use in segmenting subsequent frames. The memory bank consists of both memories from previous frames and prompted frames. The memory attention operation takes the per-frame embedding from the image encoder and conditions it on the memory bank to produce an embedding that is then passed to the mask decoder to generate the mask prediction for that frame. This is repeated for all subsequent frames.
We adopt a streaming architecture, which is a natural generalization of SAM to the video domain, processing video frames one at a time and storing information about the segmented objects in the memory. On each newly processed frame, SAM 2 uses the memory attention module to attend to the previous memories of the target object. This design allows for real-time processing of arbitrarily long videos, which is important not only for annotation efficiency in collecting the SA-V dataset but also for real-world applications—for example, in robotics.
SAM introduced the ability to output multiple valid masks when faced with ambiguity about the object being segmented in an image. For example, when a person clicks on the tire of a bike, the model can interpret this click as referring to only the tire or the entire bike and output multiple predictions. In videos, this ambiguity can extend across video frames. For example, if in one frame only the tire is visible, a click on the tire might relate to just the tire, or as more of the bike becomes visible in subsequent frames, this click could have been intended for the entire bike. To handle this ambiguity, SAM 2 creates multiple masks at each step of the video. If further prompts don’t resolve the ambiguity, the model selects the mask with the highest confidence for further propagation in the video.
The occlusion head in the SAM 2 architecture is used to predict if an object is visible or not, helping segment objects even when they become temporarily occluded.
In the image segmentation task, there is always a valid object to segment in a frame given a positive prompt. In video, it’s possible for no valid object to exist on a particular frame, for example due to the object becoming occluded or disappearing from view. To account for this new output mode, we add an additional model output (“occlusion head”) that predicts whether the object of interest is present on the current frame. This enables SAM 2 to effectively handle occlusions.
SA-V: Building the largest video segmentation dataset
Videos and masklet annotations from the SA-V dataset.
One of the challenges of extending the “segment anything” capability to video is the limited availability of annotated data for training the model. Current video segmentation datasets are small and lack sufficient coverage of diverse objects. Existing dataset annotations typically cover entire objects (e.g., person), but lack object parts (e.g., person’s jacket, hat, shoes), and datasets are often centered around specific object classes, such as people, vehicles, and animals.
To collect a large and diverse video segmentation dataset, we built a data engine, leveraging an interactive model-in-the-loop setup with human annotators. Annotators used SAM 2 to interactively annotate masklets in videos, and then the newly annotated data was used to update SAM 2 in turn. We repeated this cycle many times to iteratively improve both the model and dataset. Similar to SAM, we do not impose semantic constraints on the annotated masklets and focus on both whole objects (e.g., a person) and object parts (e.g., a person’s hat).
With SAM 2, collecting new video object segmentation masks is faster than ever before. Annotation with our tool and SAM 2 in the loop is approximately 8.4 times faster than using SAM per frame and also significantly faster than combining SAM with an off-the-shelf tracker.
Our released SA-V dataset contains over an order of magnitude more annotations and approximately 4.5 times more videos than existing video object segmentation datasets.
Highlights of the
SA-V dataset include:
More than 600,000 masklet annotations on approximately 51,000 videos.
Videos featuring geographically diverse, real-world scenarios, collected across 47 countries.
Annotations that cover whole objects, object parts, and challenging instances where objects become occluded, disappear, and reappear.
Results
Both models are initialized with the mask of the t-shirt in the first frame. For the baseline, we use the mask from SAM. SAM 2 is able to track object parts accurately throughout a video, compared to the baseline which over-segments and includes the person’s head instead of only tracking the t-shirt.
To create a unified model for image and video segmentation, we jointly train SAM 2 on image and video data by treating images as videos with a single frame. We leverage the SA-1B image dataset released last year as part of the Segment Anything project, the SA-V dataset, and an additional internal licensed video dataset.
SAM 2 (right) improves on SAM’s (left) object segmentation accuracy in images.
Key highlights that we detail in our
research paper include:
SAM 2 significantly outperforms previous approaches on interactive video segmentation across 17 zero-shot video datasets and requires approximately three times fewer human-in-the-loop interactions.
SAM 2 outperforms SAM on its 23 dataset zero-shot benchmark suite, while being six times faster.
SAM 2 excels at existing video object segmentation benchmarks (DAVIS, MOSE, LVOS, YouTube-VOS) compared to prior state-of-the-art models.
Inference with SAM 2 feels real-time at approximately 44 frames per second.
SAM 2 in the loop for video segmentation annotation is 8.4 times faster than manual per-frame annotation with SAM.
It’s important that we work to build AI experiences that work well for everyone. In order to measure the fairness of SAM 2, we conducted an evaluation on model performance across certain demographic groups. Our results show that the model has minimal performance discrepancy in video segmentation on perceived gender and little variance among the three perceived age groups we evaluated: ages 18 – 25, 26 – 50, and 50+.
Limitations
While SAM 2 demonstrates strong performance for segmenting objects in images and short videos, the model performance can be further improved—especially in challenging scenarios.
SAM 2 may lose track of objects across drastic camera viewpoint changes, after long occlusions, in crowded scenes, or in extended videos. We alleviate this issue in practice by designing the model to be interactive and enabling manual intervention with correction clicks in any frame so the target object can be recovered.
SAM 2 can sometimes confuse multiple similar looking objects in crowded scenes.
When the target object is only specified in one frame, SAM 2 can sometimes confuse objects and fail to segment the target correctly, as shown with the horses in the above video. In many cases, with additional refinement prompts in future frames, this issue can be entirely resolved and the correct masklet can be obtained throughout the video.
While SAM 2 supports the ability to segment multiple individual objects simultaneously, the efficiency of the model decreases considerably. Under the hood, SAM 2 processes each object separately, utilizing only shared per-frame embeddings, without inter-object communication. While this simplifies the model, incorporating shared object-level contextual information could aid in improving efficiency.
SAM 2 predictions can miss fine details in fast moving objects.
For complex fast moving objects, SAM 2 can sometimes miss fine details and the predictions can be unstable across frames (as shown in the video of the cyclist above). Adding further prompts to refine the prediction in the same frame or additional frames can only partially alleviate this problem During training we do not enforce any penalty on the model predictions if they jitter between frames, so temporal smoothness is not guaranteed. Improving this capability could facilitate real-world applications that require detailed localization of fine structures.
While our data engine uses SAM 2 in the loop and we’ve made significant strides in automatic masklet generation, we still rely on human annotators for some steps such as verifying masklet quality and selecting frames that require correction. Future developments could include further automating the data annotation process to enhance efficiency.
There’s still plenty more work to be done to propel this research even further. We hope the AI community will join us by building with SAM 2 and the resources we’ve released. Together, we can accelerate open science to build powerful new experiences and use cases that benefit people and society.
Putting SAM 2 to work
While many of Meta FAIR’s models used in public demos are hosted on Amazon SageMaker, the session-based requirements of the SAM 2 model pushed up against the boundaries of what our team believed was previously possible on AWS AI Infra. Thanks to the advanced model deployment and managed inference capabilities offered by Amazon SageMaker, we’ve been able to make the SAM 2 release possible—focusing on building state of the art AI models and unique AI demo experiences.
In the future, SAM 2 could be used as part of a larger AI system to identify everyday items via AR glasses that could prompt users with reminders and instructions.
We encourage the AI community to download the model, use the dataset, and try our demo. By sharing this research, we hope to contribute to accelerating progress in universal video and image segmentation and related perception tasks. We look forward to seeing the new insights and useful experiences that will be created by releasing this research to the community.
Download the model
Get the dataset
Read the paper
Try the demo
Visit the SAM 2 website































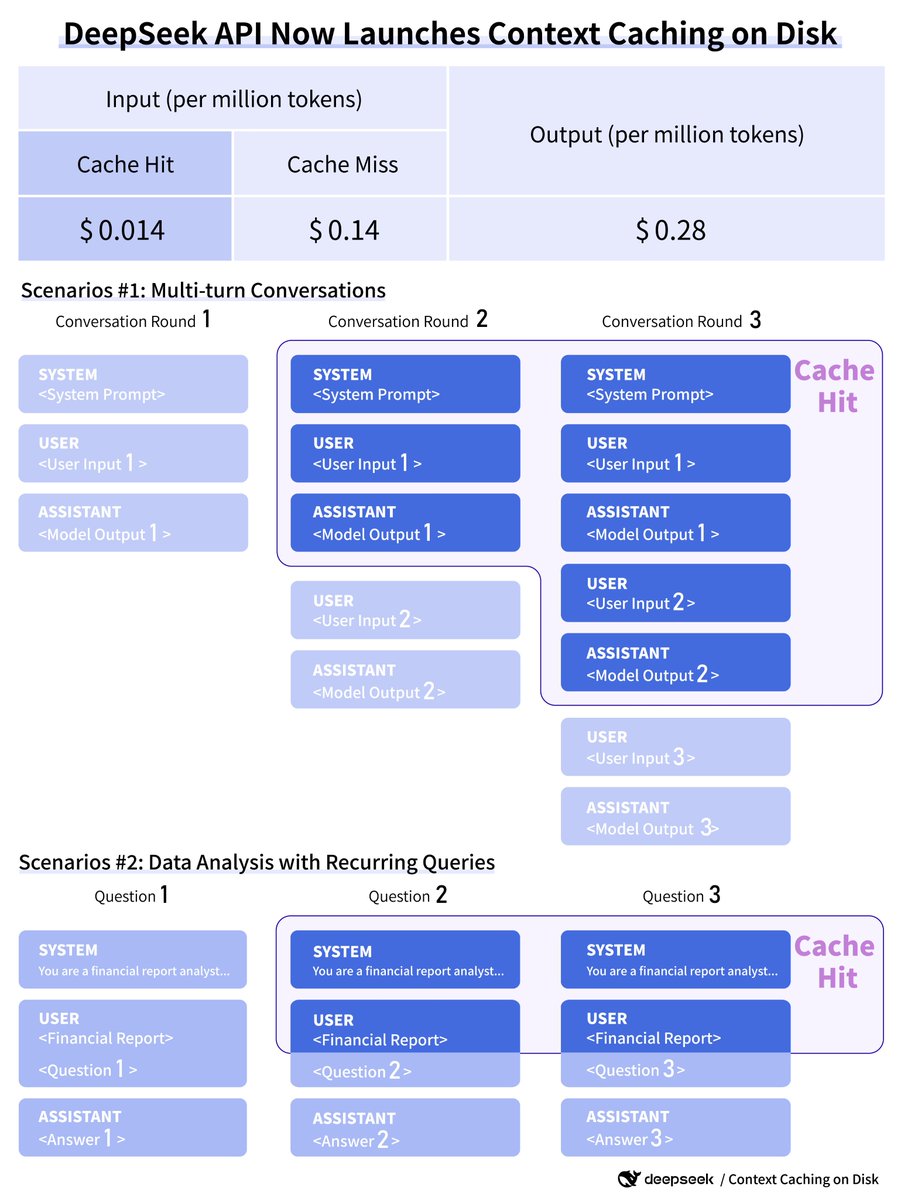
 Exciting news! DeepSeek API now launches context caching on disk, with no code changes required! This new feature automatically caches frequently referenced contexts on distributed storage, slashing API costs by up to 90%. For a 128K prompt with high reference, the first token latency is cut from 13s to just 500ms.
Exciting news! DeepSeek API now launches context caching on disk, with no code changes required! This new feature automatically caches frequently referenced contexts on distributed storage, slashing API costs by up to 90%. For a 128K prompt with high reference, the first token latency is cut from 13s to just 500ms. 
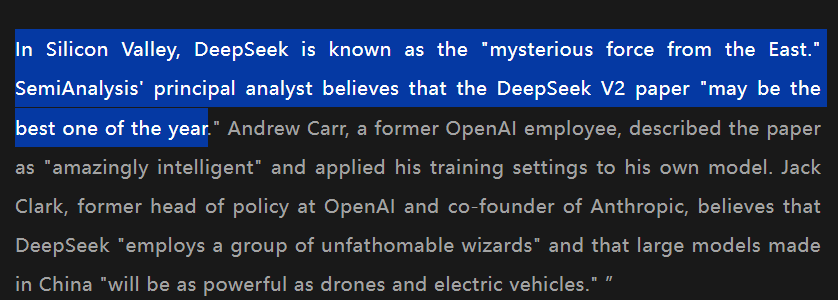
 you (I'm literally just a whale)
you (I'm literally just a whale)