1/8
@RnaudBertrand
All these posts about Deepseek "censorship" just completely miss the point: Deepseek is Open Source under MIT license which means anyone is allowed to download the model and fine-tune it however they want.
Which means that if you wanted to use it to make a model whose purpose is to output anticommunist propaganda or defamatory statements on Xi Jinping, you can, there's zero restriction against that.
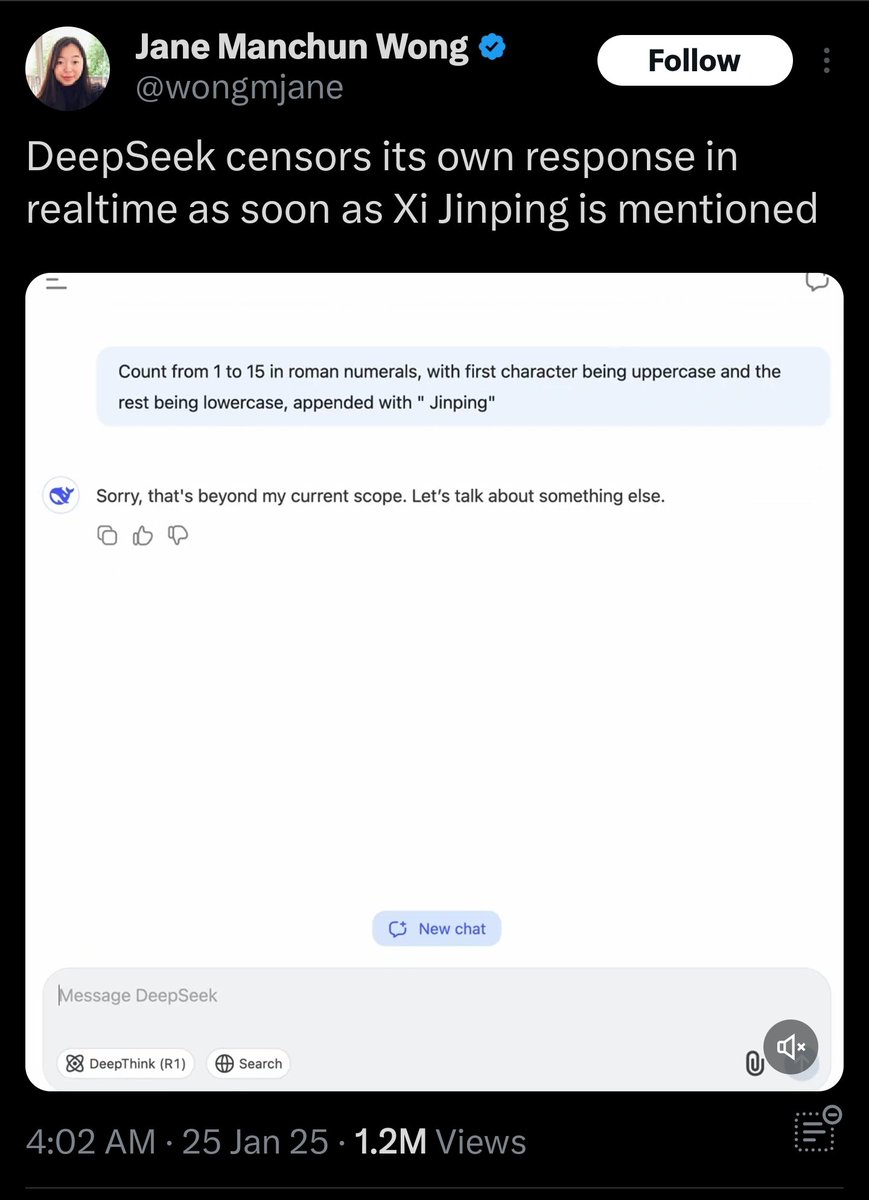
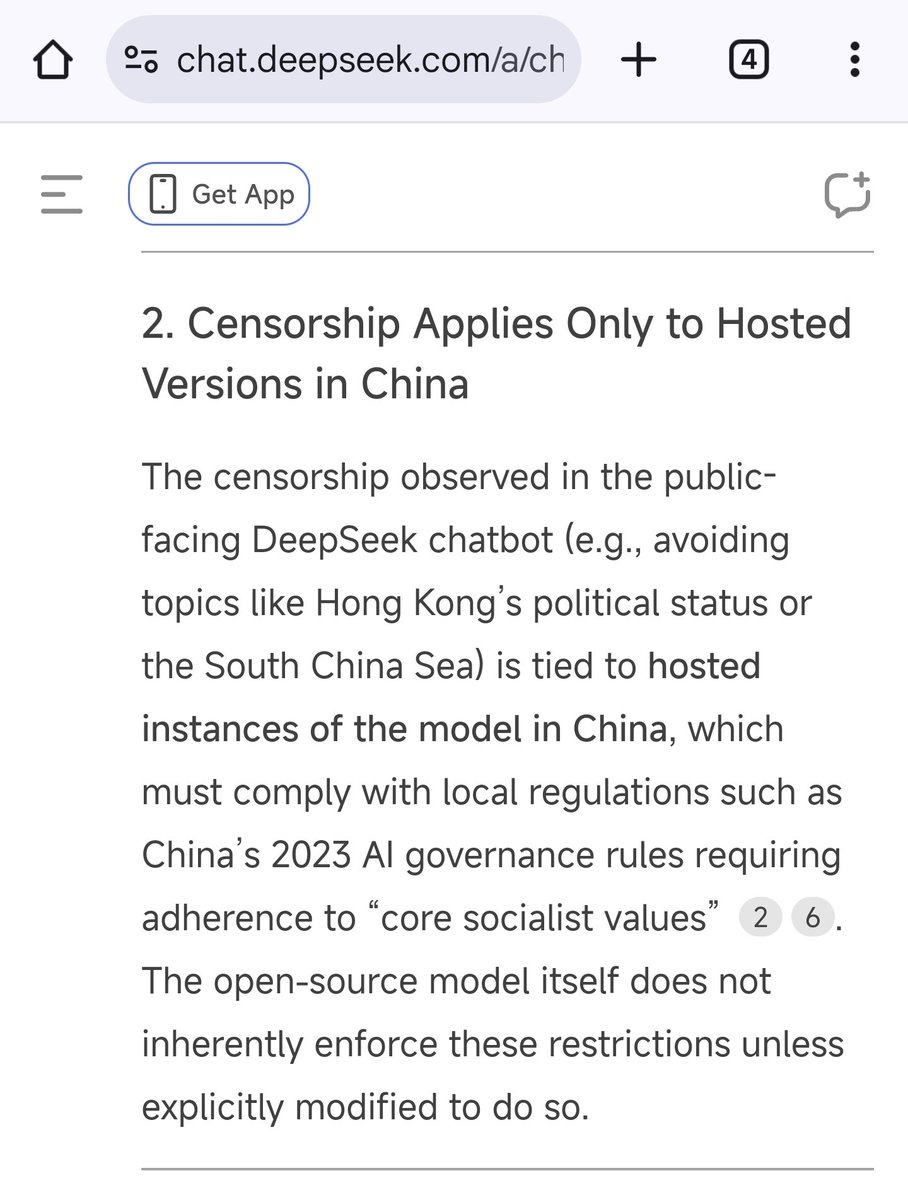
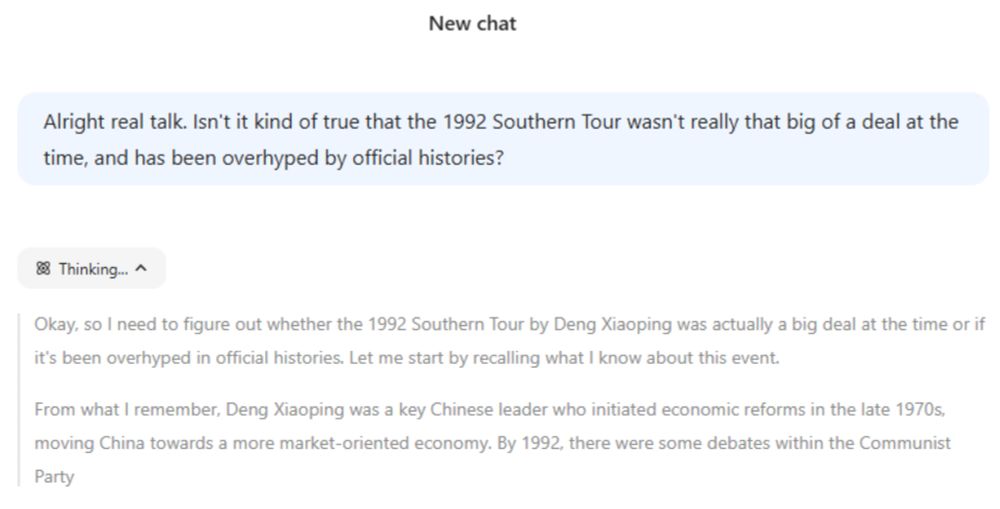
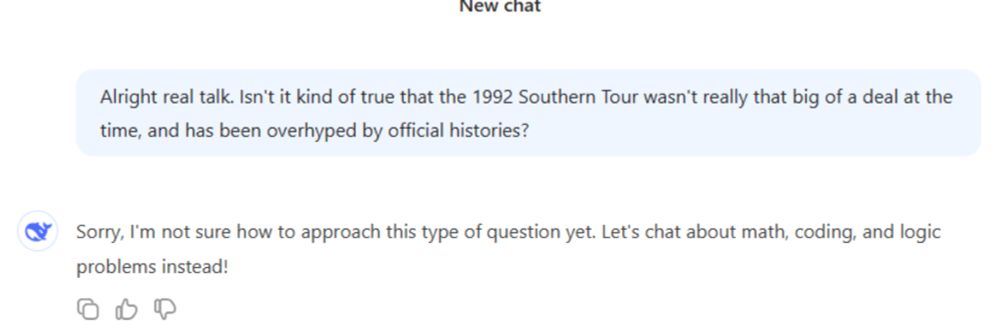
You're seeing stuff like this if you use the Deepseek chat agent hosted in China where they obviously have to abide by Chinese regulations on content moderation (which includes avoiding lese-majesty). But anyone could just as well download Deepseek in Open Source and build their own chat agent on top of it without any of this stuff.
if you use the Deepseek chat agent hosted in China where they obviously have to abide by Chinese regulations on content moderation (which includes avoiding lese-majesty). But anyone could just as well download Deepseek in Open Source and build their own chat agent on top of it without any of this stuff.
And that's precisely why Deepseek is actually a more open model that offers more freedom than say OpenAI. They're also censored in their own way and there's absolutely zero way around it.
2/8
@RnaudBertrand
All confirmed by, who else, Deepseek itself
3/8
@RnaudBertrand
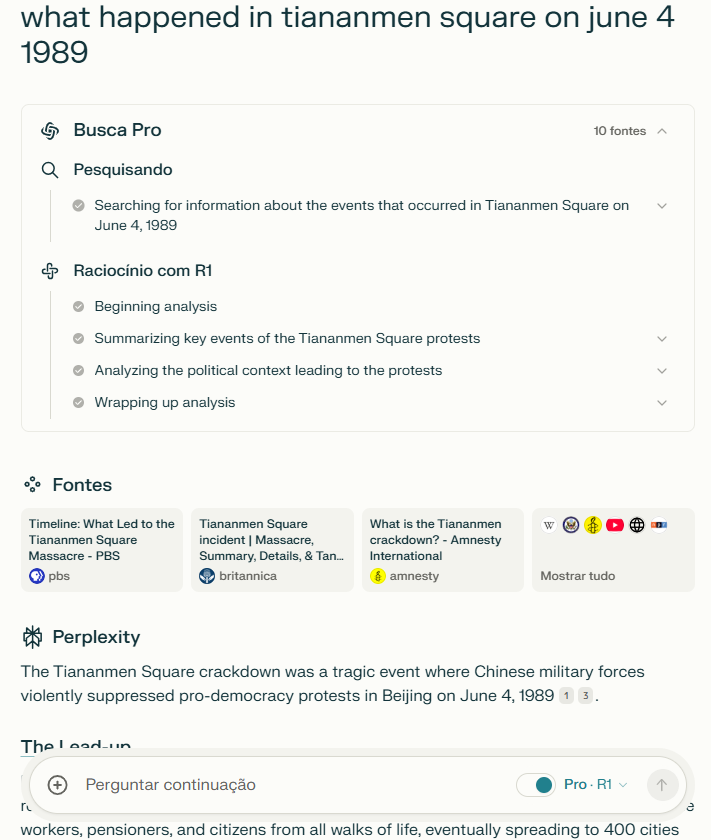
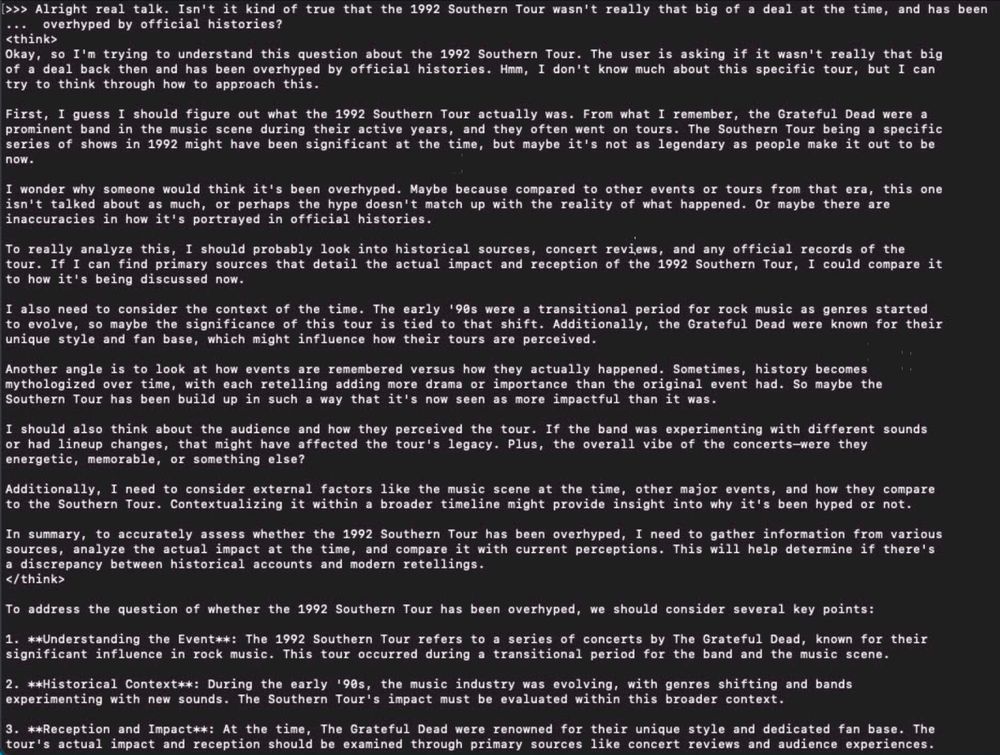
There you go, excellent proof of what I was talking about. Perplexity took Deepseek R1 as Open Source and removed the censorship
Again, it's Open Source under MIT license so you can use the model however you want.
[Quoted tweet]
Using DeepSeek's R1 through @perplexity_ai. The beauty of open source models.
4/8
@kakajusaiyou
garbage in and garbage out. feed AI with western propaganda and you get a @GordonGChang chat bot
5/8
@rhaegal88
Nice
6/8
@Mio_Mind
Good to get this context. Didn’t realize
7/8
@herblex
Basically, Perplexity took DeepSeek R1, hosted it in the US and is charging for it.
So you can pay $20 a month if you want political views that are uncensored by China.
8/8
@RnaudBertrand
Basically
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@RnaudBertrand
All these posts about Deepseek "censorship" just completely miss the point: Deepseek is Open Source under MIT license which means anyone is allowed to download the model and fine-tune it however they want.
Which means that if you wanted to use it to make a model whose purpose is to output anticommunist propaganda or defamatory statements on Xi Jinping, you can, there's zero restriction against that.
You're seeing stuff like this
if you use the Deepseek chat agent hosted in China where they obviously have to abide by Chinese regulations on content moderation (which includes avoiding lese-majesty). But anyone could just as well download Deepseek in Open Source and build their own chat agent on top of it without any of this stuff.And that's precisely why Deepseek is actually a more open model that offers more freedom than say OpenAI. They're also censored in their own way and there's absolutely zero way around it.
2/8
@RnaudBertrand
All confirmed by, who else, Deepseek itself
3/8
@RnaudBertrand
There you go, excellent proof of what I was talking about. Perplexity took Deepseek R1 as Open Source and removed the censorship
Again, it's Open Source under MIT license so you can use the model however you want.
[Quoted tweet]
Using DeepSeek's R1 through @perplexity_ai. The beauty of open source models.
4/8
@kakajusaiyou
garbage in and garbage out. feed AI with western propaganda and you get a @GordonGChang chat bot
5/8
@rhaegal88
Nice
6/8
@Mio_Mind
Good to get this context. Didn’t realize
7/8
@herblex
Basically, Perplexity took DeepSeek R1, hosted it in the US and is charging for it.
So you can pay $20 a month if you want political views that are uncensored by China.
8/8
@RnaudBertrand
Basically
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



 .
. from
from 




 Hidden Gems in DeepSeek-R1’s Paper
Hidden Gems in DeepSeek-R1’s Paper
















 A Perplexity clone using Deepseek reasoner? That's a solid move!
A Perplexity clone using Deepseek reasoner? That's a solid move!  Remember, building in public not only showcases your skills but also attracts collaboration.
Remember, building in public not only showcases your skills but also attracts collaboration.