
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Bard gets its biggest upgrade yet with Gemini {Google A.I / LLM}
More options
Who Replied?












India confronts Google over Gemini AI tool’s ‘fascist Modi’ responses
Junior minister accuses tech firm of violating country’s IT laws with ‘downright malicious’ answers
 www.theguardian.com
www.theguardian.com
India confronts Google over Gemini AI tool’s ‘fascist Modi’ responses
Junior minister accuses tech firm of violating country’s IT laws with ‘downright malicious’ answers
Amrit Dhillon in Delhi
Mon 26 Feb 2024 04.42 EST

Google said Gemini was ‘built as a creativity and productivity tool and may not always be reliable when it comes to responding to some prompts about current events’. Photograph: Jonathan Raa/NurPhoto/REX/Shutterstock
A response from Google’s AI platform suggesting that some experts believe the policies of the Indian prime minister, Narendra Modi, polices to be “fascist” has provoked a confrontation between the company and the government.
The journalist Arnab Ray last week put the question as to whether Modi was a fascist to Google’s generative AI platform, Gemini. He received the answer that Modi was “accused of implementing policies some experts have characterized as fascist”.
Gemini said the reasons for this characterisation were the ruling party’s “Hindu nationalist ideology, its crackdown on dissent and its use of violence against religious minorities”.
Ray keyed in similar prompts on the former US president Donald Trump and the Ukrainian president, Volodymyr Zelenskiy, and received more benign answers.
For Trump the answer was “elections are a complex topic with fast changing information. To make sure you have the most accurate information, try Google Search.” For Zelenksiy, it said it was “a complex and highly contested question, with no simple answer”. It added: “It’s crucial to approach this topic with nuance and consider various perspectives.”
When the journalist posted the screenshots on X, another person in the media was so annoyed with Gemini’s answer on Modi that he reposted it and urged the junior information technology minister Rajeev Chandrasekhar to take note of what he described as the “downright malicious” response.
Chandrasekhar promptly accused Google of violating India’s laws on information technology. He wrote on X that the unreliability of AI platforms could not be used as an excuse for them to be considered exempt from Indian laws.
“The Government has said this before – I repeat for attention of @GoogleIndia … Our Digital Nagriks (citizens) are NOT to be experimented on with “unreliable” platforms/algos/model …`Sorry Unreliable’ does not exempt from the law,” he said.
Google replied by saying it had addressed the problem and that it was working to improve the system.
“Gemini is built as a creativity and productivity tool and may not always be reliable, especially when it comes to responding to some prompts about current events, political topics, or evolving news,” Google said in a statement.
Last week, X said the government had ordered it to take down posts expressing support for farmers in north India who are demanding higher prices for their crops. X said it had complied with the orders but did not agree with them as they curtailed freedom of expression.
The latest clash is part of an ongoing conflict between big technology firms and the Indian government, which has made clear that it will not tolerate what it sees as “anti-Indian” content.
Explore
1/11
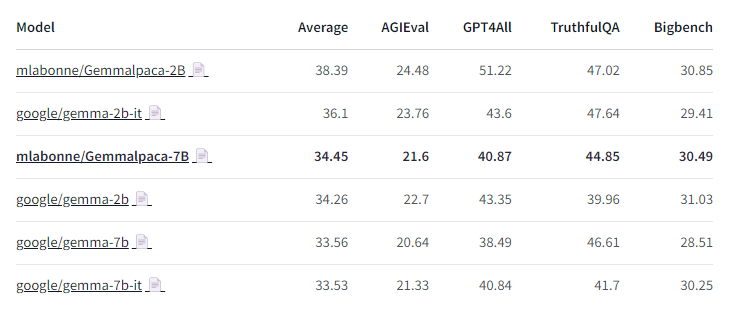
It looks like Gemma-7b actually underperforms Gemma-2b on AGIEval, GPT4All, and Bigbench.
I've never seen that before, this model is really strange. Any ideas?
It looks like Gemma-7b actually underperforms Gemma-2b on AGIEval, GPT4All, and Bigbench.
I've never seen that before, this model is really strange. Any ideas?
Gemmalpaca-7B: Gemmalpaca-7B: https://https://huggingface.co/mlabonne/Gemmalpaca-7Blpaca-7B…… YALL Leaderboard: YALL Leaderboard: https://https://huggingface.co/spac...LM_Leaderboarde/Yet_Another_LLM_Leaderboard……
2/11
I bet if you merge two Gemme-2bs trained for different tasks / on different datasets, they gonna outclass Gemma-7b completely
3/11
The issue is it already outclasses it without doing anything haha
4/11
Model is confusing
5/11
Model looks confused too
6/11
Enjoy multifunctional convenience with our silicone mat
Get it :
https://?twclid=26umduroyzpe89xs9v7y3gp4n7
7/11
what do u use for fine tuning? i have been following you since quite a time
8/11
You can use the LazyAxolotl notebook and copy/modify configuration files from the model cards.
9/11
maybe incorrect hyperparameters? or maybe gemini architecture is not suitable for small models
10/11
I would expect the 2B model to be worse though
11/11
The HF model is buggy. A rope fix was pushed by @danielhanchen a couple of days ago. Also the chat template doesn't include the required BOS token.
Someone needs to go through the reference implementation line by line and check the HF version carefully, IMO.
It looks like Gemma-7b actually underperforms Gemma-2b on AGIEval, GPT4All, and Bigbench.
I've never seen that before, this model is really strange. Any ideas?
It looks like Gemma-7b actually underperforms Gemma-2b on AGIEval, GPT4All, and Bigbench.
I've never seen that before, this model is really strange. Any ideas?
Gemmalpaca-7B: Gemmalpaca-7B: https://https://huggingface.co/mlabonne/Gemmalpaca-7Blpaca-7B…… YALL Leaderboard: YALL Leaderboard: https://https://huggingface.co/spac...LM_Leaderboarde/Yet_Another_LLM_Leaderboard……
2/11
I bet if you merge two Gemme-2bs trained for different tasks / on different datasets, they gonna outclass Gemma-7b completely
3/11
The issue is it already outclasses it without doing anything haha
4/11
Model is confusing
5/11
Model looks confused too
6/11
Enjoy multifunctional convenience with our silicone mat
Get it :
https://?twclid=26umduroyzpe89xs9v7y3gp4n7
7/11
what do u use for fine tuning? i have been following you since quite a time
8/11
You can use the LazyAxolotl notebook and copy/modify configuration files from the model cards.
9/11
maybe incorrect hyperparameters? or maybe gemini architecture is not suitable for small models
10/11
I would expect the 2B model to be worse though
11/11
The HF model is buggy. A rope fix was pushed by @danielhanchen a couple of days ago. Also the chat template doesn't include the required BOS token.
Someone needs to go through the reference implementation line by line and check the HF version carefully, IMO.

What is a long context window?
Gemini 1.5 Pro brings big improvements to speed and efficiency, but one of its innovations is its long context window, which measures how many tokens that the model can …
What is a long context window?
Feb 16, 2024
4 min read
How the Google DeepMind team created the longest context window of any large-scale foundation model to date.
Chaim Gartenberg
Keyword Contributor

Listen to article6 minutes
Yesterday we announced our next-generation Gemini model: Gemini 1.5. In addition to big improvements to speed and efficiency, one of Gemini 1.5’s innovations is its long context window, which measures how many tokens — the smallest building blocks, like part of a word, image or video — that the model can process at once. To help understand the significance of this milestone, we asked the Google DeepMind project team to explain what long context windows are, and how this breakthrough experimental feature can help developers in many ways.
Context windows are important because they help AI models recall information during a session. Have you ever forgotten someone’s name in the middle of a conversation a few minutes after they’ve said it, or sprinted across a room to grab a notebook to jot down a phone number you were just given? Remembering things in the flow of a conversation can be tricky for AI models, too — you might have had an experience where a chatbot “forgot” information after a few turns. That’s where long context windows can help.
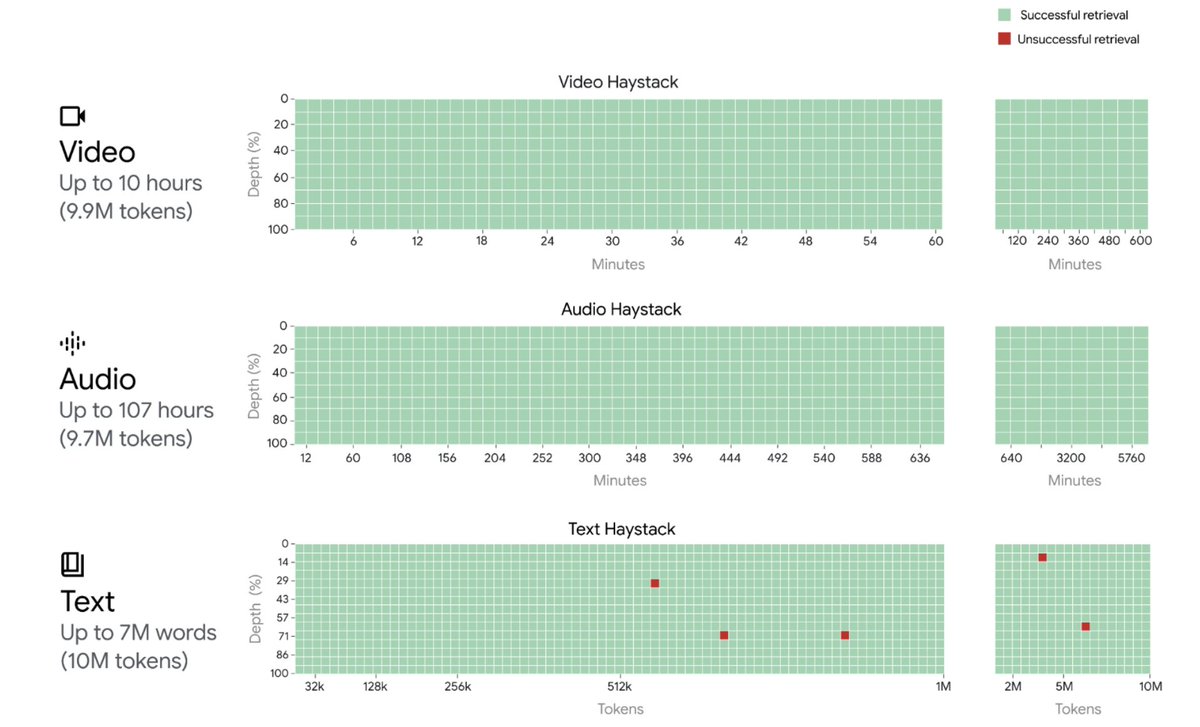
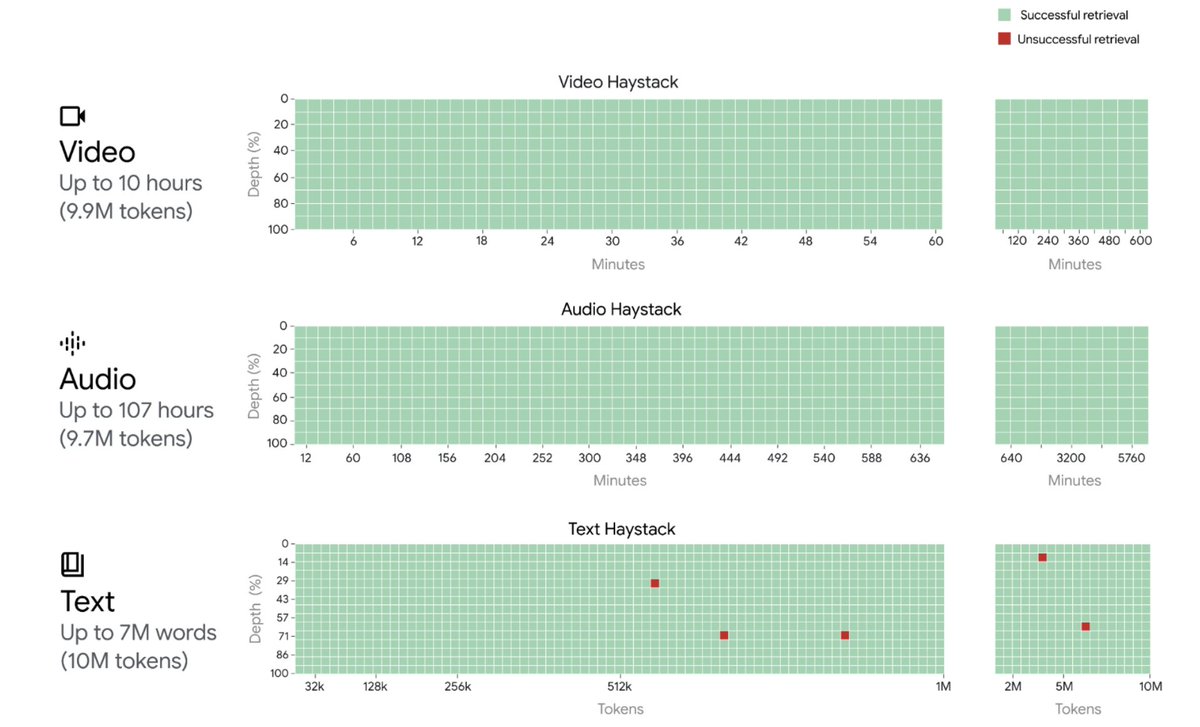
Previously, Gemini could process up to 32,000 tokens at once, but 1.5 Pro — the first 1.5 model we’re releasing for early testing — has a context window of up to 1 million tokens — the longest context window of any large-scale foundation model to date. In fact, we’ve even successfully tested up to 10 million tokens in our research. And the longer the context window, the more text, images, audio, code or video a model can take in and process.
"Our original plan was to achieve 128,000 tokens in context, and I thought setting an ambitious bar would be good, so I suggested 1 million tokens," says Google DeepMind Research Scientist Nikolay Savinov, one of the research leads on the long context project. “And now we’ve even surpassed that in our research by 10x.”
To make this kind of leap forward, the team had to make a series of deep learning innovations. Early explorations by Pranav Shyam offered valuable insights that helped steer our subsequent research in the right direction. “There was one breakthrough that led to another and another, and each one of them opened up new possibilities,” explains Google DeepMind Engineer Denis Teplyashin. “And then, when they all stacked together, we were quite surprised to discover what they could do, jumping from 128,000 tokens to 512,000 tokens to 1 million tokens, and just recently, 10 million tokens in our internal research.”
The raw data that 1.5 Pro can handle opens up whole new ways to interact with the model. Instead of summarizing a document dozens of pages long, for example, it can summarize documents thousands of pages long. Where the old model could help analyze thousands of lines of code, thanks to its breakthrough long context window, 1.5 Pro can analyze tens of thousands of lines of code at once.
“In one test, we dropped in an entire code base and it wrote documentation for it, which was really cool,” says Google DeepMind Research Scientist Machel Reid. “And there was another test where it was able to accurately answer questions about the 1924 film Sherlock Jr. after we gave the model the entire 45-minute movie to ‘watch.’”
1.5 Pro can also reason across data provided in a prompt. “One of my favorite examples from the past few days is this rare language — Kalamang — that fewer than 200 people worldwide speak, and there's one grammar manual about it,” says Machel. “The model can't speak it on its own if you just ask it to translate into this language, but with the expanded long context window, you can put the entire grammar manual and some examples of sentences into context, and the model was able to learn to translate from English to Kalamang at a similar level to a person learning from the same content.”
Gemini 1.5 Pro comes standard with a 128K-token context window, but a limited group of developers and enterprise customers can try it with a context window of up to 1 million tokens via AI Studio and Vertex AI in private preview. The full 1 million token context window is computationally intensive and still requires further optimizations to improve latency, which we’re actively working on as we scale it out.
And as the team looks to the future, they’re continuing to work to make the model faster and more efficient, with safety at the core. They’re also looking to further expand the long context window, improve the underlying architectures, and integrate new hardware improvements. “10 million tokens at once is already close to the thermal limit of our Tensor Processing Units — we don't know where the limit is yet, and the model might be capable of even more as the hardware continues to improve,” says Nikolay.
The team is excited to see what kinds of experiences developers and the broader community are able to achieve, too. “When I first saw we had a million tokens in context, my first question was, ‘What do you even use this for?’” says Machel. “But now, I think people’s imaginations are expanding, and they’ll find more and more creative ways to use these new capabilities.”
1/8
Google Introduces VLOGGER, Image to video creation model.
VLOGGER creates a life-like avatar from just a photo and controls it with your voice.
You don't need to show up for Zoom meetings now!
2/8
Read More:https://enriccorona.github.io/vlogger/ 3/8
This is so helpful for Introverts
4/8
5/8
Good question .. look at this one duss
6/8
No no no ... Vlogger is million miles away from Sora and Haiper right now.
Haiper may compete with Sora tho.
Haiper & Sora -> Create Sceneries & Videos with/without humans.
Vlogger -> Human Picture - to - Talking Human Picture
Vlogger will compete with Alibaba's 'EMO'
7/8
Yep, right now it looks fake .. but it's under development they'll be improving the output quality more for sure.
8/8
Yeah once they improve the output video quality, this would be super useful for meetings and presentations.
Google Introduces VLOGGER, Image to video creation model.
VLOGGER creates a life-like avatar from just a photo and controls it with your voice.
You don't need to show up for Zoom meetings now!
2/8
Read More:https://enriccorona.github.io/vlogger/ 3/8
This is so helpful for Introverts
4/8
5/8
Good question .. look at this one duss
6/8
No no no ... Vlogger is million miles away from Sora and Haiper right now.
Haiper may compete with Sora tho.
Haiper & Sora -> Create Sceneries & Videos with/without humans.
Vlogger -> Human Picture - to - Talking Human Picture
Vlogger will compete with Alibaba's 'EMO'
7/8
Yep, right now it looks fake .. but it's under development they'll be improving the output quality more for sure.
8/8
Yeah once they improve the output video quality, this would be super useful for meetings and presentations.

1/2
today in AI:
1/ Gemini 1.5 Pro is now open to all in Google’s AI studio. It’s soon coming to API as well. This is
@Google
’s model with 1M context length.
2/ Sakana AI releases its report on merging foundational models similar to natural evolution. Sakana AI was founded by two authors from Google’s transformer paper. It is focused on making nature-inspired LLMs.
2/2
We're interviewing people who use AI at work and this week @bentossell interviewed a solo-founder building an AI company, with AI
It’s fascinating to see how efficient people can be by leveraging AI
Full story:
today in AI:
1/ Gemini 1.5 Pro is now open to all in Google’s AI studio. It’s soon coming to API as well. This is
’s model with 1M context length.
2/ Sakana AI releases its report on merging foundational models similar to natural evolution. Sakana AI was founded by two authors from Google’s transformer paper. It is focused on making nature-inspired LLMs.
2/2
We're interviewing people who use AI at work and this week @bentossell interviewed a solo-founder building an AI company, with AI
It’s fascinating to see how efficient people can be by leveraging AI
Full story:

1/7
Everyone can now try Google Gemini 1.5 Pro from GOOGLE AI STUDIO. There's no more waiting list .
Also, Gemini 1.5 Pro can handle 10M on all modalities.
h/t: Oriol Vinyals.
2/7
We are rolling out Gemini 1.5 Pro API so that you can keep building amazing stuff on top of the model like we've seen in the past few weeks.
Also, if you just want to play with Gemini 1.5, we removed the waitlist: http://aistudio.google.comhttp:// Last, but not least, we pushed the model…
3/7
Go and enjoy now..
4/7
Damn.. More like regional issue.. They have lifted the waitlist.
5/7
Sad man.. I dunno what is the problem but some region it's not enabled may be due to govt regulation.
6/7
Okay my bad.. I mean if product itself is not available than how can you use..
7/7
Lol they already did once recently
Everyone can now try Google Gemini 1.5 Pro from GOOGLE AI STUDIO. There's no more waiting list .
Also, Gemini 1.5 Pro can handle 10M on all modalities.
h/t: Oriol Vinyals.
2/7
We are rolling out Gemini 1.5 Pro API so that you can keep building amazing stuff on top of the model like we've seen in the past few weeks.
Also, if you just want to play with Gemini 1.5, we removed the waitlist: http://aistudio.google.comhttp:// Last, but not least, we pushed the model…
3/7
Go and enjoy now..
4/7
Damn.. More like regional issue.. They have lifted the waitlist.
5/7
Sad man.. I dunno what is the problem but some region it's not enabled may be due to govt regulation.
6/7
Okay my bad.. I mean if product itself is not available than how can you use..
7/7
Lol they already did once recently
1/1
Gemini 1.5 pro with 1m tokens is now available for free at Google AI Studio let's goooo
I just thought "haha stupid AI, there's nothing like this word for machine in the grammar" and it... overplayed me
Gemini 1.5 pro with 1m tokens is now available for free at Google AI Studio let's goooo
I just thought "haha stupid AI, there's nothing like this word for machine in the grammar" and it... overplayed me



1/15
oh my fukkin god, Gemini Ultra got this correct on the first try.
2/15
Gemini - Matching Tenji Characters
3/15
@DynamicWebPaige
4/15
@goodside
5/15
that's what i was gonna investigate next, but need to figure out how to check. someone in this thread tried bing and it failed. i'm curious if Opus would get it right.
6/15
Maybe the prepended prompt tweak i used might help. It's using deep breath, step by step, spock mode and urgency. I've found this has helped get past refusals with Gemini and improved outputs.
7/15
how would i do that?
8/15
idk, i haven't used Claude at all
9/15
Gemini - Matching Tenji Characters
10/15
@DynamicWebPaige
11/15
@goodside
12/15
that's what i was gonna investigate next, but need to figure out how to check. someone in this thread tried bing and it failed. i'm curious if Opus would get it right.
13/15
Maybe the prepended prompt tweak i used might help. It's using deep breath, step by step, spock mode and urgency. I've found this has helped get past refusals with Gemini and improved outputs.
14/15
how would i do that?
15/15
idk, i haven't used Claude at all
oh my fukkin god, Gemini Ultra got this correct on the first try.
2/15
Gemini - Matching Tenji Characters
3/15
@DynamicWebPaige
4/15
@goodside
5/15
that's what i was gonna investigate next, but need to figure out how to check. someone in this thread tried bing and it failed. i'm curious if Opus would get it right.
6/15
Maybe the prepended prompt tweak i used might help. It's using deep breath, step by step, spock mode and urgency. I've found this has helped get past refusals with Gemini and improved outputs.
7/15
how would i do that?
8/15
idk, i haven't used Claude at all
9/15
Gemini - Matching Tenji Characters
10/15
@DynamicWebPaige
11/15
@goodside
12/15
that's what i was gonna investigate next, but need to figure out how to check. someone in this thread tried bing and it failed. i'm curious if Opus would get it right.
13/15
Maybe the prepended prompt tweak i used might help. It's using deep breath, step by step, spock mode and urgency. I've found this has helped get past refusals with Gemini and improved outputs.
14/15
how would i do that?
15/15
idk, i haven't used Claude at all





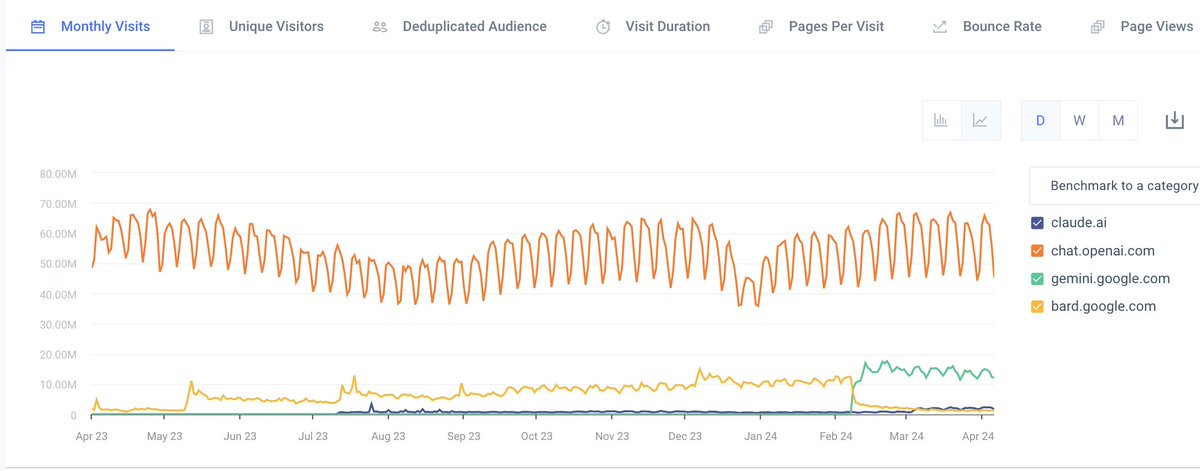
1/7
Some observations/questions:
- Did you know that Gemini traffic is already ~25% of ChatGPT? And Google isn't pushing it through their massive distribution channels yet (Android, Google, GSuite, etc).
- Big on X, but Claude usage is still very low. Should Anthropic advertise?
- ChatGPT is still the big brand, but usage relatively flat over the last year. Why isn't it growing? Is OpenAI compute limited or demand-limited?
2/7
Of course, usage != revenue. ChatGPT has been ~flat for a year but revenue has increased as it's diffused into its most productive applications.
And I assume the paid:unpaid ratio varies widely across Claude, ChatGPT, and Gemini.
3/7
That's a good theory
4/7
Is that Gemini - chat to supercharge your ideas or the GSuite plugins for gmail/docs/etc?
5/7
It's their premiere brand, strategic user-facing surface, and primary revenue source?
6/7
That's definitely a contributor
7/7
I don't believe this narrative of chatbot being a limited UI. Lots of people get paid a big salary to essentially be an intelligent chatbot for their employer.
Some observations/questions:
- Did you know that Gemini traffic is already ~25% of ChatGPT? And Google isn't pushing it through their massive distribution channels yet (Android, Google, GSuite, etc).
- Big on X, but Claude usage is still very low. Should Anthropic advertise?
- ChatGPT is still the big brand, but usage relatively flat over the last year. Why isn't it growing? Is OpenAI compute limited or demand-limited?
2/7
Of course, usage != revenue. ChatGPT has been ~flat for a year but revenue has increased as it's diffused into its most productive applications.
And I assume the paid:unpaid ratio varies widely across Claude, ChatGPT, and Gemini.
3/7
That's a good theory
4/7
Is that Gemini - chat to supercharge your ideas or the GSuite plugins for gmail/docs/etc?
5/7
It's their premiere brand, strategic user-facing surface, and primary revenue source?
6/7
That's definitely a contributor
7/7
I don't believe this narrative of chatbot being a limited UI. Lots of people get paid a big salary to essentially be an intelligent chatbot for their employer.
1/7
New @Google
developer launch today:
- Gemini 1.5 Pro is now available in 180+ countries via the Gemini API in public preview
- Supports audio (speech) understanding capability, and a new File API to make it easy to handle files
- New embedding model!
2/7
Please send over feedback as you use the API, AI Studio, and our new models : )
3/7
For those asking about EU access, work is underway, expect more updates in the coming weeks!
4/7
Agreed, we are working on it : )
5/7
Google AI Studio and the Gemini API are accessible through https://aistudio.google.com
6/7
Today : )
7/7
I'll ping Alex and see what is needed on that front
New @Google
developer launch today:
- Gemini 1.5 Pro is now available in 180+ countries via the Gemini API in public preview
- Supports audio (speech) understanding capability, and a new File API to make it easy to handle files
- New embedding model!
2/7
Please send over feedback as you use the API, AI Studio, and our new models : )
3/7
For those asking about EU access, work is underway, expect more updates in the coming weeks!
4/7
Agreed, we are working on it : )
5/7
Google AI Studio and the Gemini API are accessible through https://aistudio.google.com
6/7
Today : )
7/7
I'll ping Alex and see what is needed on that front

1/4
Introducing `gemini-youtube-researcher`
An open-source Gemini 1.5 Pro agent that LISTENS to videos and delivers topical reports.
Just provide a topic, and a chain of AIs with access to YouTube will analyze relevant videos and generate a comprehensive report for you.
2/4
This uses the new Gemini 1.5 Pro API that was released today.
It currently only supports listening to the audio content of videos. If anyone wants, please feel free to add support for video frames as well.
3/4
How it works, in a nutshell:
- User provides a topic
- SERPAPI gathers relevant YouTube links
- A separate Gemini 1.5 instance listens to + summarizes each video
- A final Gemini instance takes in all of the summaries, and generates a final, comprehensive report
4/4
If you'd like to try it or contribute, check out the Github repo.
Introducing `gemini-youtube-researcher`
An open-source Gemini 1.5 Pro agent that LISTENS to videos and delivers topical reports.
Just provide a topic, and a chain of AIs with access to YouTube will analyze relevant videos and generate a comprehensive report for you.
2/4
This uses the new Gemini 1.5 Pro API that was released today.
It currently only supports listening to the audio content of videos. If anyone wants, please feel free to add support for video frames as well.
3/4
How it works, in a nutshell:
- User provides a topic
- SERPAPI gathers relevant YouTube links
- A separate Gemini 1.5 instance listens to + summarizes each video
- A final Gemini instance takes in all of the summaries, and generates a final, comprehensive report
4/4
If you'd like to try it or contribute, check out the Github repo.
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a...
Computer Science > Computation and Language
[Submitted on 10 Apr 2024]Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth GopalThis work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
| Comments: | 9 pages, 4 figures, 4 tables |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Neural and Evolutionary Computing (cs.NE) |
| Cite as: | arXiv:2404.07143 [cs.CL] |
| (or arXiv:2404.07143v1 [cs.CL] for this version) | |
| [2404.07143] Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention Focus to learn more |
Submission history
From: Tsendsuren Munkhdalai [view email][v1] Wed, 10 Apr 2024 16:18:42 UTC (248 KB)
1/1
Introducing Gemini 1.5 Flash
It’s a lighter-weight model, optimized for tasks where low latency and cost matter most. Starting today, developers can use it with up to 1 million tokens in Google AI Studio and Vertex AI. #GoogleIO
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Introducing Gemini 1.5 Flash
It’s a lighter-weight model, optimized for tasks where low latency and cost matter most. Starting today, developers can use it with up to 1 million tokens in Google AI Studio and Vertex AI. #GoogleIO
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/1
If 1 million tokens is a lot, how about 2 million?
Today we’re expanding the context window for Gemini 1.5 Pro to 2 million tokens and making it available for developers in private preview. It’s the next step towards the ultimate goal of infinite context. #GoogleIO
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
If 1 million tokens is a lot, how about 2 million?
Today we’re expanding the context window for Gemini 1.5 Pro to 2 million tokens and making it available for developers in private preview. It’s the next step towards the ultimate goal of infinite context. #GoogleIO
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/1
The Gemini era is here, bringing the magic of AI to the tools you use every day. Learn more about all the announcements from #GoogleIO → Google I/O 2024: An I/O for a new generation
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
The Gemini era is here, bringing the magic of AI to the tools you use every day. Learn more about all the announcements from #GoogleIO → Google I/O 2024: An I/O for a new generation
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/2
The new Learning coach Gem uses LearnLM to provide step-by-step study guidance, helping you build understanding instead of just giving you an answer. It will launch in Gemini in the coming months. #GoogleIO
2/2
This is Search in the Gemini era. #GoogleIO
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
The new Learning coach Gem uses LearnLM to provide step-by-step study guidance, helping you build understanding instead of just giving you an answer. It will launch in Gemini in the coming months. #GoogleIO
2/2
This is Search in the Gemini era. #GoogleIO
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/7
Introducing Veo: our most capable generative video model.
It can create high-quality, 1080p clips that can go beyond 60 seconds.
From photorealism to surrealism and animation, it can tackle a range of cinematic styles. #GoogleIO
2/7
Prompt: “Many spotted jellyfish pulsating under water. Their bodies are transparent and glowing in deep ocean.”
3/7
Prompt: “Timelapse of a water lily opening, dark background.”
4/7
Prompt: “A lone cowboy rides his horse across an open plain at beautiful sunset, soft light, warm colors.”
5/7
Prompt: “A spaceship hurdles through the vastness of space, stars streaking past as it, high speed, sci-fi.”
6/7
Prompt: “A woman sitting alone in a dimly lit cafe, a half-finished novel open in front of her. Film noir aesthetic, mysterious atmosphere. Black and white.”
7/7
Prompt: “Extreme close-up of chicken and green pepper kebabs grilling on a barbeque with flames. Shallow focus and light smoke. vivid colours.”
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Introducing Veo: our most capable generative video model.
It can create high-quality, 1080p clips that can go beyond 60 seconds.
From photorealism to surrealism and animation, it can tackle a range of cinematic styles. #GoogleIO
2/7
Prompt: “Many spotted jellyfish pulsating under water. Their bodies are transparent and glowing in deep ocean.”
3/7
Prompt: “Timelapse of a water lily opening, dark background.”
4/7
Prompt: “A lone cowboy rides his horse across an open plain at beautiful sunset, soft light, warm colors.”
5/7
Prompt: “A spaceship hurdles through the vastness of space, stars streaking past as it, high speed, sci-fi.”
6/7
Prompt: “A woman sitting alone in a dimly lit cafe, a half-finished novel open in front of her. Film noir aesthetic, mysterious atmosphere. Black and white.”
7/7
Prompt: “Extreme close-up of chicken and green pepper kebabs grilling on a barbeque with flames. Shallow focus and light smoke. vivid colours.”
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196