Coqui, Freeing Speech.

coqui.ai
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
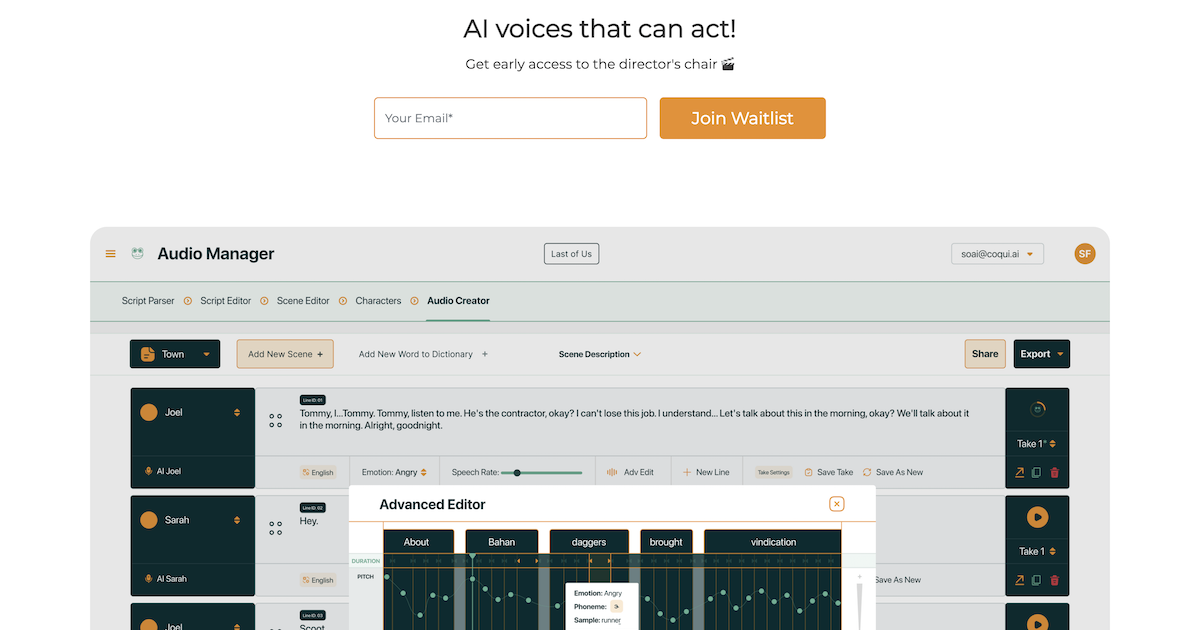
ⓍTTS is a Voice generation model that lets you clone voices into different languages by using just a quick 3-second audio clip. Built on Tortoise, ⓍTTS has important model changes that make cross-language voice cloning and multi-lingual speech generation super easy. There is no need for an excessive amount of training data that spans countless hours.
This is the same model that powers
Coqui Studio, and
Coqui API, however we apply a few tricks to make it faster and support streaming inference.
Features
- Supports 14 languages.
- Voice cloning with just a 3-second audio clip.
- Emotion and style transfer by cloning.
- Cross-language voice cloning.
- Multi-lingual speech generation.
- 24khz sampling rate.
Languages
As of now, XTTS-v1 (v1.1) supports 14 languages:
English, Spanish, French, German, Italian, Portuguese, Polish, Turkish, Russian, Dutch, Czech, Arabic, Chinese, and Japanese.
Stay tuned as we continue to add support for more languages. If you have any language requests, please feel free to reach out!
Code
The current implementation only supports inference.
Discover amazing ML apps made by the community
huggingface.co
Discover amazing ML apps made by the community
huggingface.co