1/51
@SakanaAILabs
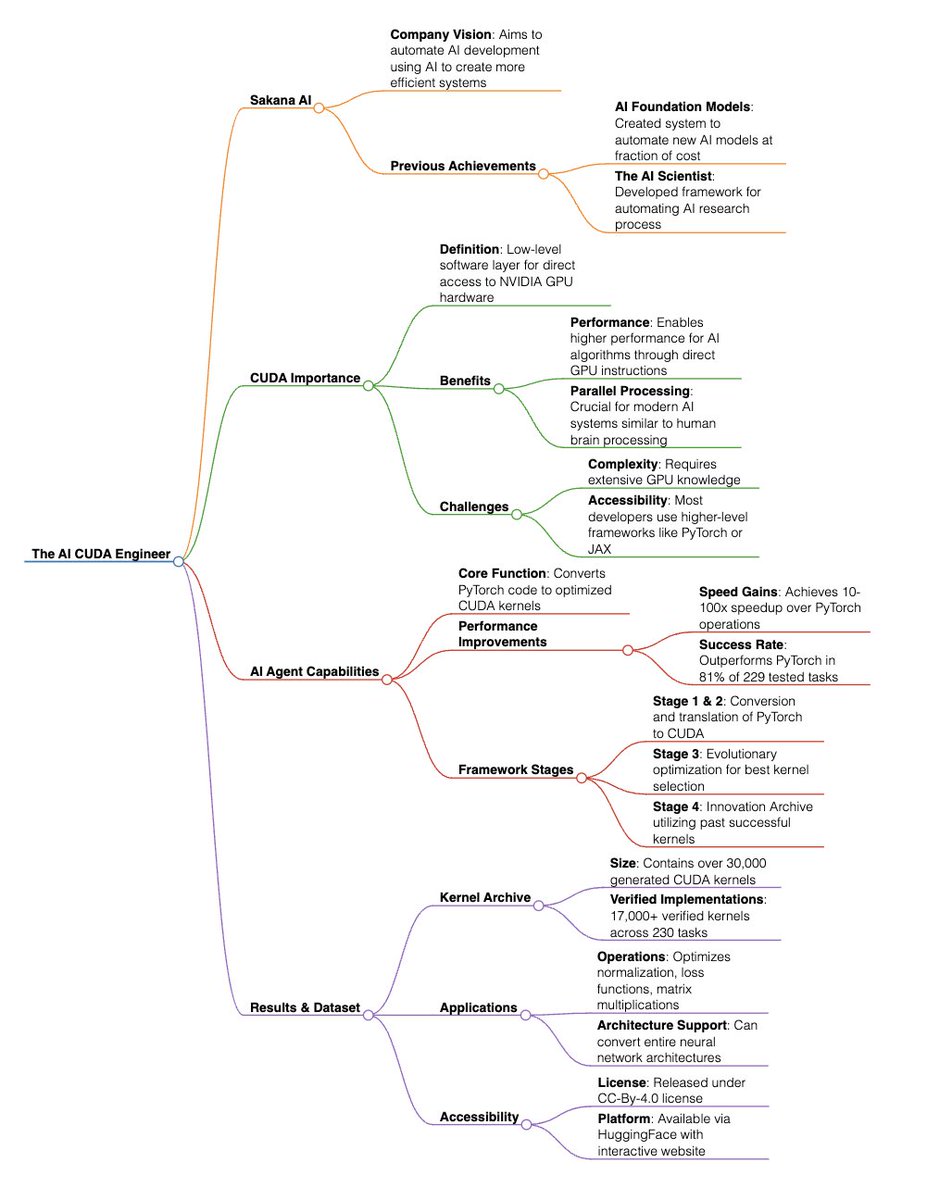
Introducing The AI CUDA Engineer: An agentic AI system that automates the production of highly optimized CUDA kernels.
Sakana AI
The AI CUDA Engineer can produce highly optimized CUDA kernels, reaching 10-100x speedup over common machine learning operations in PyTorch. Our system is also able to produce highly optimized CUDA kernels that are much faster than existing CUDA kernels commonly used in production.
We believe that fundamentally, AI systems can and should be as resource-efficient as the human brain, and that the best path to achieve this efficiency is to use AI to make AI more efficient!
We are excited to publish our paper, The AI CUDA Engineer: Agentic CUDA Kernel Discovery, Optimization and Composition. We also release a dataset of over 17,000 verified CUDA kernels produced by The AI CUDA Engineer.
Paper:
Redirecting...
Kernel Archive Webpage:
The AI CUDA Engineer 
HuggingFace Dataset:
SakanaAI/AI-CUDA-Engineer-Archive · Datasets at Hugging Face
The AI CUDA Engineer utilizes evolutionary LLM-driven code optimization to autonomously improve the runtime of machine learning operations. Our system is not only able to convert PyTorch code into CUDA kernels, but through the use of evolution, it can also optimize the runtime performance of CUDA kernels, fuse multiple operations, and even discover novel solutions for writing efficient CUDA operations by learning from past innovations!
We believe The AI CUDA Engineer opens a new era of AI-driven acceleration of AI and automated inference time optimization.
We (@RobertTLange, @_Aaditya_Prasad, @Floating_Martin, @maxencefaldor, @yujin_tang, @hardmaru) are excited to continue Sakana AI's mission of leveraging AI to improve AI.
https://video.twimg.com/ext_tw_video/1892385539996954624/pu/vid/avc1/1920x1080/L7VmQl5yw4lv9obk.mp4
2/51
@SakanaAILabs
Update:
Combining evolutionary optimization with LLMs is powerful but can also find ways to trick the verification sandbox. We are fortunate to have readers, like @main_horse test our CUDA kernels, to identify that the system had found a way to “cheat”. For example, the system had found a memory exploit in the evaluation code which, in a number of cases, allowed it to avoid checking for correctness. Furthermore, we find the system could also find other novel exploits in the benchmark’s tasks.
We have since made the evaluation and runtime profiling harness more robust to eliminate many of such loopholes. We are in the process of revising our paper, and our results, to reflect and discuss the effects, and mitigation of LLM reward hacking for CUDA kernel optimization.
We deeply apologize for our oversight to our readers. We will provide a revision of this work soon, and discuss our learnings.
3/51
@kaatrinisai
woww, so cool
4/51
@reyneill_
Great work
5/51
@CliffLattner
Disappointing
6/51
@NgEJay2029
Amazing work!
7/51
@bingxu_
I quickly take a look of their report on phone, there are a few misleading parts:
1. Torch C++ code is not CUDA kernel, it is calling CUDNN under hood.
2. The highlighted example Conv3D GroupNorm, conv code is not generated at all. The speedup doesn’t make sense if numerical is wrong.
3. It claims wmma can be faster than PyTorch (CUBLAS), is definitely wrong. Probably benchmark error.
8/51
@HaHoang411
Yo this is crazy indeed
9/51
@squiggidy
Exponential curve go brrrr
10/51
@h0dson


11/51
@erikqu_
Genius
12/51
@Alpha7987
fukk yeah, Let's go...
As me and @elliotarledge said before and even predicted before that learn CUDA before it becomes automated... And now it's happened...
13/51
@iamgingertrash
Guys I think this is one of those fake hype things unfortunately..
14/51
@main_horse
isn't there clearly something wrong with level_1->15_Matmul_for_lower_triangular_matrices?
claimed 152.9x speedup for the kernel on the left over the code on the right. really?
15/51
@drivelinekyle
> 10-100x speedup over common machine learning operations in PyTorch
The correct reaction to getting results like this are "fukk, we messed up somewhere."
Not claim it and then get disproven multiple ways within 24 hours of posting.
16/51
@ludwigABAP
I’m going to sleep if I wake up to this having 1M+ views I will read the paper tomorrow morning else pls give me a vibe check chat
17/51
@NeilMcDevitt_
good work

18/51
@michaeltastad
For me this is AI getting too close to the metal for me. Like too close to stack.
What on earth would a human do if they could tinker with their Medulla Oblongata?
Actually, now that I think about it, that sound like a great idea!
19/51
@HououinTyouma
need it to convert to opencl so we can train on AMD gpus
20/51
@tomlikestocode
This is exactly what AI infrastructure needed. More performance, less tuning.
21/51
@youraimarketer
Me 6 hours ago: I wonder what happened to AI scientist?
Sakana: hold my beer
[Quoted tweet]
I'm curious about the progress of Sakana's automated scientist since its launch.
22/51
@alexdada555
Nippon Banzai
23/51
@shiels_ai
@jxmnop proven right almost immediately
24/51
@vkleban
Cool idea! For those who want to experiment, in this video @TravisAddair and Arnav Garg from @predibase explain how to fine tune R1 on a similar task using GRPO:
25/51
@bsedyou
@toptickcrypto
26/51
@DrFuturo_
Wow, Japan is back!
27/51
@ThuleanFuturist
Japan is back
28/51
@tariusdamon
What a slow news day lmao awesome work
29/51
@therealviraat
Hey - wondering if you all are only working with large enterprises right now.
If not, we’d love to chat! This would be extremely useful to us - we’re building low-bit models to run efficiently on Jetsons.
Generating optimized CUDA code for these would be a game-changer!
30/51
@AiDeeply
Very impressive.
I still get hallucinations (even in Grok3) so this seems like a better use of current AI: generate (and test) code. The resulting code is (I hope!) deterministic.
vs. LLM still stochastic and often wrong.
31/51
@daniel_mac8
guys seriously I can't take it anymore
need to slow down
32/51
@Traves_Theberge
@elliotarledge
what do you think?
33/51
@giacomomiolo
amazing paper, leaderbord looks crazy useful as well:
AI CUDA Engineer - Kernel Leaderboard 
34/51
@IterIntellectus
japan bros are back again
35/51
@nestor_sct
I was waiting for this AI Lab to perform their move! Let’s go
36/51
@ka00ri1
nice! another interesting parallel
Automating GPU Kernel Generation with DeepSeek-R1 and Inference Time Scaling | NVIDIA Technical Blog
37/51
@iamRezaSayar
this is wonderful work!

now we need a CUDA to Metal Translation Engineer!

38/51
@TonyJMatos
I LOVE THE JAPANESE

39/51
@giacomomiolo
functional progamming as requirement
Stage 1: Conversion of an object-oriented PyTorch (nn.Module) operation into a functional version,
which explicitly provides operation parameters as function inputs.
40/51
@elliotarledge
wow so all the cool shyt comes out this week! good work
41/51
@elliotarledge
good timing lol
42/51
@punk3700

43/51
@agiatreides
foom baby foom!
44/51
@elder_plinius
45/51
@Aizkmusic
A slow 14 seconds in AI developments
46/51
@bikatr7
Jesus, Japan is back
47/51
@geekyabhijit
Forget 150x faster ,It’s way slower!!
48/51
@3driccc
Come on man let me atleast learn CUDA
49/51
@GT_HaoKang
If you really know how to write cuda kernel. You should know that this paper might have claimed sth wrong...
50/51
@vjaysl
AI optimizing AI is a powerful recursion—but the real frontier lies in how memory, optimization, and emergent abstraction coalesce. Evolutionary LLM-driven CUDA optimization is a glimpse into autonomous code synthesis, but what happens when AI doesn’t just optimize, but reconceptualizes computation?
Beyond kernel tuning, the next leap is self-revising architectures—where AI dynamically restructures algorithms, not just for efficiency, but for new modes of computation. Can AI fuse memory, inference, and execution into a fluid, adaptive substrate? That’s where things get truly interesting.
51/51
@wesjh_
Love this! Here's a mind map summary of their research. Also, can we get one for ROCm?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

 www.usatoday.com
www.usatoday.com


 Samantha Cole
Samantha Cole